Вредоносное ПО (malware) - это назойливые или опасные программы,...


Сегментация изображений с U-Net на практике
Введение
В этом блог посте мы посмотрим как Unet работает, как реализовать его, и какие данные нужны для его обучения. Для этого мы будем рассматривать:
Мы не будем следовать на 100% за статьей, но мы постараемся реализовать ее суть, адаптировать под наши нужды.
Презентация проблемы
В этой задаче нам дано изображение машины и его бинарная маска(локализующая положение машины на изображении). Мы хотим создать модель, которая будет будет способна отделять изображение машины от фона с попиксельной точностью более 99%.
Для понимания того что мы хотим, gif изображение ниже:
Изображение слева - это исходное изображение, справа - маска, которая будет применяться на изображение. Мы будем использовать Unet нейронную сеть, которая будет учиться автоматически создавать маску.
Структура кода
Код был максимально упрощен для понимания как это работает. Основной код находится в этом файле main.py , разберем его построчно.
Код
Мы будем итеративно проходить через код в main.py и через статью. Не волнуйтесь о деталях, спрятанных в других файлах проекта: нужные мы продемонстрируем по мере необходимости.
Давайте
начнем
с
начала
:
def
main
():
# Hyperparameters
input_img_resize =
(572
, 572
) # The resize size of the input images of the neural net
output_img_resize =
(388
, 388
) # The resize size of the output images of the neural net
batch_size =
3
epochs =
50
threshold =
0.
5
validation_size =
0.
2
sample_size =
None
# -- Optional parameters
threads =
cpu_count()
use_cuda =
torch.cuda.is_available()
script_dir =
os.path.dirname(os.path.abspath(__file__
))
# Training callbacks
tb_viz_cb =
TensorboardVisualizerCallback(os.path.join(script_dir,"../logs/tb_viz"
))
tb_logs_cb =
TensorboardLoggerCallback(os.path.join(script_dir,"../logs/tb_logs"
))
model_saver_cb =
ModelSaverCallback(os.path.join(script_dir,"../output/models/model_"
+
helpers.get_model_timestamp()), verbose=
True
)
В первом разделе вы определяете свои гиперпараметры, их можете настроить по своему усмотрению, например в зависимости от вашей памяти GPU. Optimal parametes определяют некоторые полезные параметры и callbacks . TensorboardVisualizerCallback - это класс, который будет сохранять предсказания в tensorboard в каждую эпоху тренировочного процесса, TensorboardLoggerCallback сохранит значения функций потерь и попиксельную «точность» в tensorboard . И наконец ModelSaverCallback сохранит вашу модель после завершения обучения.
# Download the datasets
ds_fetcher =
DatasetFetcher
()
ds_fetcher.
download_dataset()
Этот раздел автоматически загружает и извлекает набор данных из Kaggle. Обратите внимание, что для успешной работы этого участка кода вам необходимо иметь учетную запись Kaggle с логином и паролем, которые должны быть помещены в переменные окружения KAGGLE_USER и KAGGLE_PASSWD перед запуском скрипта. Также требуется принять правила конкурса, перед загрузкой данных. Это можно сделать на вкладке загрузки данных конкурса
# Get the path to the files for the neural net X_train, y_train, X_valid, y_valid = ds_fetcher.get_train_files(sample_size= sample_size, validation_size= validation_size) full_x_test = ds_fetcher.get_test_files(sample_size) # Testing callbacks pred_saver_cb = PredictionsSaverCallback(os.path.join (script_dir,"../output/submit.csv.gz" ), origin_img_size, threshold)
Эта строка определяет callback функцию для теста (или предсказания). Она будет сохранять предсказания в файле gzip каждый раз, когда будет произведена новая партия предсказания. Таким образом, предсказания не будут сохранятся в памяти, так как они очень большие по размеру.
После окончания процесса предсказания вы можете отправить полученный файл submit.csv.gz из выходной папки в Kaggle.
# -- Define our neural net architecture
# The original paper has 1
input channel, in
our case
we have 3
(RGB
)
net =
unet_origin.
UNetOriginal
((3
, *img_resize))
classifier =
nn.
classifier.
CarvanaClassifier
(net, epochs)
optimizer =
optim.
SGD
(net.
parameters()
, lr=
0.01
, momentum=
0.99
)
train_ds =
TrainImageDataset
(X_train
, y_train, input_img_resize, output_img_resize, X_transform
=
aug.
augment_img)
train_loader =
DataLoader
(train_ds, batch_size,
sampler=
RandomSampler
(train_ds),
num_workers=
threads,
pin_memory=
use_cuda)
valid_ds =
TrainImageDataset
(X_valid
, y_valid, input_img_resize, output_img_resize, threshold=
threshold)
valid_loader =
DataLoader
(valid_ds, batch_size,
sampler=
SequentialSampler
(valid_ds),
num_workers=
threads,
pin_memory=
use_cuda)
print
("Training on {} samples and validating on {} samples "
.
format(len(train_loader.
dataset), len(valid_loader.
dataset)))
# Train the classifier
classifier.
train(train_loader, valid_loader, epochs, callbacks=
)
Наконец, мы делаем то же самое, что и выше, но для прогона предсказания. Мы вызываем наш pred_saver_cb.close_saver() , чтобы очистить и закрыть файл, который содержит предсказания.
Реализация архитектуры нейронной сети
Статья Unet представляет подход для сегментации медицинских изображений. Однако оказывается этот подход также можно использовать и для других задач сегментации. В том числе и для той, над которой мы сейчас будем работать.
Перед тем, как идти вперед, вы должны прочитать статью полностью хотя бы один раз. Не волнуйтесь, если вы не получили полного понимания математического аппарата, вы можете пропустить этот раздел, также как главу «Эксперименты». Наша цель заключается в получении общей картины.
Задача оригинальной статьи отличается от нашей, нам нужно будет адаптировать некоторые части соответственно нашим потребностям.
В то время, когда была написана работа, были пропущены 2 вещи, которые сейчас необходимы для ускорения сходимости нейронной сети:
Первое был изобретено всего за 3 месяца до Unet , и вероятно слишком рано, чтобы авторы Unet добавили его в свою статью.
На сегодняшний день BatchNorm используется практически везде. Вы можете избавиться от него в коде, если хотите оценить статью на 100%, но вы можете не дожить до момента, когда сеть сойдется.
Что касается графических процессоров, в статье говорится:
To minimize the overhead and make maximum use of the GPU memory, we favor large input tiles over a large batch size and hence reduce the batch to a single image
Они использовали GPU с 6 ГБ RAM, но в настоящее время у GPU больше памяти, для размещения изображений в одном batch’e. Текущий batch равный трем, работает для графического процессора в GPU с 8 гб RAM. Если у вас нет такой видеокарты, попробуйте уменьшить batch до 2 или 1.
Что касается методов augmentations (то есть искажения исходного изображения по какому либо паттерну), рассматриваемых в статье, мы будем использовать отличные от описываемых в статье, поскольку наши изображения сильно отличаются от биомедицинских изображений.
Теперь давайте начнем с самого начала, проектируя архитектуру нейронной сети:
Вот как выглядит Unet. Вы можете найти эквивалентную реализацию Pytorch в модуле nn.unet_origin.py.
Все классы в этом файле имеют как минимум 2 метода:
Давайте рассмотрим детали реализации:
Мы отслеживаем вывод последней операции ConvBnRelu в x_trace и возвращаем ее, потому что мы будем конкатенировать этот вывод с помощью стеков декодера.
Обратите внимание, что он учитывает операцию обрезки / конкатенации (окруженную оранжевым), передавая в down_tensor, который является не чем иным, как тензором x_trace, возвращаемым нашим StackEncoder .
Если вы хотите понять больше деталей каждого блока, поместите контрольную точку отладки в метод forward каждого класса, чтобы подробно просмотреть объекты. Вы также можете распечатать форму ваших тензоров вывода между слоями, выполнив печать (x.size() ).
Тренировка нейронной сети
Теперь к реальному миру. Согласно статье:
The energy function is computed by a pixel-wise soft-max over the final feature map combined with the cross-entropy loss function.
Дело в том, что в нашем случае мы хотим использовать dice coefficient как функцию потерь вместо того, что они называют «энергетической функцией», так как это показатель, используемый в соревновании Kaggle , который определяется:
X является нашим предсказанием и Y - правильно размеченной маской на текущем объекте. |X| означает мощность множества X (количество элементов в этом множестве) и ∩ для пересечения между X и Y .
Код для dice coefficient можно найти в nn.losses.SoftDiceLoss .
class SoftDiceLoss (nn.Module): def __init__(self, weight= None, size_average= True): super (SoftDiceLoss, self).__init__() def forward(self, logits, targets): smooth = 1 num = targets.size (0 ) probs = F.sigmoid(logits) m1 = probs.view(num, - 1 ) m2 = targets.view(num, - 1 ) intersection = (m1 * m2) score = 2 . * (intersection.sum(1 ) + smooth) / (m1.sum(1 ) + m2.sum(1 ) + smooth) score = 1 - score.sum() / num return scoreПричина, по которой пересечение реализуется как умножение, и мощность в виде sum() по axis 1 (сумма из трех каналов) заключается в том, что предсказания и цель являются one-hot encoded векторами.
Например, предположим, что предсказание на пикселе (0, 0) равно 0,567, а цель равна 1, получаем 0,567 * 1 = 0,567. Если цель равна 0, мы получаем 0 в этой позиции пикселя.
Мы также использовали плавный коэффициент 1 для обратного распространения. Если предсказание является жестким порогом, равным 0 и 1, трудно обратно распространять dice loss .
Затем мы сравним dice loss с кросс-энтропией, чтобы получить нашу функцию полной потери, которую вы можете найти в методе _criterion из nn.Classifier.CarvanaClassifier . Согласно оригинальной статье они также используют weight map в функции потери кросс-энтропии, чтобы придать некоторым пикселям большее ошибки во время тренировки. В нашем случае нам не нужна такая вещь, поэтому мы просто используем кросс-энтропию без какого-либо weight map.
2. Оптимизатор
Поскольку мы имеем дело не с биомедицинскими изображениями, мы будем использовать наши собственные augmentations . Код можно найти в img.augmentation.augment_img . Там мы выполняем случайное смещение, поворот, переворот и масштабирование.
Тренировка нейронной сети
Теперь можно начать обучение. По мере прохождения каждой эпохи вы сможете визуализировать, предсказания вашей модели на валидационном наборе.
Для этого вам нужно запустить Tensorboard в папке logs с помощью команды:
Tensorboard --logdir=./logs
Пример того, что вы сможете увидеть в Tensorboard после эпохи 1:
Пороговая обработка, вероятно, самый простой метод сегментации, что привлекает к нему большое внимание специалистов. Метод ориентирован на обработку изображений, отдельные однородные участки которых различаются средней яркостью. Простейшим и вместе с тем часто применяемым видом сегментации является бинарная сегментация, когда имеется только два типа однородных участков. При этом преобразование каждой точки исходного изображения в выходное выполняется по правилу:
(7.1)
где - единственный параметр обработки, называемый порогом. Уровни выходной яркости и , могут быть произвольными, они лишь выполняют функции меток, при помощи которых осуществляется разметка получаемой карты - отнесение ее точек к классам или соответственно. Если образуемый препарат подготавливается для визуального восприятия, то часто их значения соответствуют уровням черного и белого. Если существует более двух классов, то при пороговой обработке должно быть задано семейство порогов, отделяющих яркости различных классов друг от друга.
Центральным вопросом пороговой сегментации является определение порогов, которое должно выполняться автоматически. Применяемые в настоящее время методы автоматического определения порогов подробно описаны в обзоре . Разнообразие методов очень велико, однако в основном они базируются на анализе гистограммы исходного изображения.
Пусть , - гистограмма исходного цифрового изображения. Примем, что его диапазон яркостей заключен в пределах от 0 (уровень черного) до 255 (уровень белого). Первоначальная идея гистограммного метода определения порога основывалась на предположении о том, что распределения вероятностей для каждого класса унимодальны (содержат по одному пику), а точки границ, разделяющих участки разных классов на изображении, малочисленны. Этим предположениям должна отвечать гистограмма, которая имеет многомодальный характер. Отдельные моды соответствуют различным классам, а разделяющие их впадины - малочисленным по количеству входящих в них точек граничным областям. Пороги сегментации находятся при этом по положению впадин. Рис. 7.1 иллюстрирует сказанное выше применительно к случаю двух классов. В действительности воспользоваться такими простыми соображениями для выбора порога удается крайне редко. Дело в том, что реальные гистограммы обычно сильно изрезаны, что иллюстрирует приводимый па рис.7.2, в результат эксперимента. Это служит первым препятствием для определения точек минимума. Вторым препятствием является то, что границы между однородными участками на изображении бывают размыты, вследствие чего уровень гистограммы в тех ее частях, которые отображают точки границы, возрастает. Очевидно, это приводит к уменьшению провалов в гистограмме или даже их исчезновению.

Рис.7.1.К выбору порога бинарной сегментации
Один из эффективных путей преодоления этих трудностей состоит и определении порога на основе так называемого дискриминантного критерия. Рассмотрим этот подход применительно к двум классам, поскольку обобщение на случай большего числа классов не составляет принципиальной проблемы. Итак, считаем, что распределение ,построено для изображения, содержащего два типа участков, причем существует оптимальная граница , разделяющая их наилучшим образом в некотором смысле. Для определения оптимального порога строим дискриминантную функцию , , аргумент которой имеет смысл пробного порога. Его значение, максимизирующее функцию , является оптимальным порогом . Рассмотрим построение дискриминантной функции.
Пусть - гипотетическое значение порога, разбивающее распределение , на два класса. При этом обычно не играет большой роли, к какому из классов будут отнесены точки изображения, имеющие яркость , в силу малочисленности граничных точек, разделяющие участки разных классов. Вероятность того, что наугад взятая точка кадра принадлежит классу , равна
 (7.2)
(7.2)
Аналогично вероятность ее принадлежности к классу определяется формулой
 (7.3)
(7.3)
причем в силу нормировки распределения вероятностей имеет место равенство
Далее считаем, что участок распределения
, , ограниченный точкой
, описывает
часть изображения, принадлежащую , а участок , ![]() - принадлежащую . Это позволяет ввести
в рассмотрение два распределения и , соответствующих и , конструируя их из распределения
при
помощи выражений:
- принадлежащую . Это позволяет ввести
в рассмотрение два распределения и , соответствующих и , конструируя их из распределения
при
помощи выражений:
![]()
![]()
![]()
Здесь делением на вероятности и обеспечивается нормировка вводимых условных распределений.
Для образованных таким образом распределений вероятностей могут быть найдены моменты. Выражения для математических ожиданий и имеют вид
 (7.4)
(7.4)
где  - ненормированное
математическое ожидание для ,
- ненормированное
математическое ожидание для ,  - математическое ожидание
для всего кадра.
- математическое ожидание
для всего кадра.
Аналогично, дисперсия дня всего кадра определяется выражением
 (7.6)
(7.6)
Для построения дискриминантной функции дополнительно вводим еще один энергетический параметр , называемый межклассовой дисперсией:
Безразмерная дискриминантная функция определяется выражением
![]() (7.8)
(7.8)
Оптимальным, как говорилось выше, считается порог, отвечающим требованию
![]() (7.9)
(7.9)
Поясним смысл критерия (7.9). Знаменатель в выражении (7.8) является дисперсией всего кадра и, следовательно, от величины пробного порога , разбивающего изображение на классы, не зависит. Поэтому точка максимума выражения (7.8) совпадает с точкой максимума числителя, т.е. определяется характером зависимости межклассовой дисперсии (7.7) от порога . При его стремлении к нулю вероятность , как следует из (7.2), также стремится к нулю. Поскольку при этом все изображение относится к классу , имеет место тенденция . Следовательно, оба слагаемых в (7.7) становятся равными нулю. Это же наблюдается и при другом крайнем значении порога =255. В силу неотрицательности величин, входящих в (7.7) и (7.9), и равенства функции нулю на краях области определения, внутри этой области существует максимум, абсцисса которого и принимается за оптимальный порог. Следует отметить качественный характер этих соображений. Более детальные исследования показывают, например, что при обработке некоторых изображений дискриминантная функция имеет несколько максимумов даже при наличии на изображении только двух классов. Это, в частности, проявляется, когда суммарные площади участков, занятых классами и ,существенно различны. Поэтому задача в общем случае несколько усложняется необходимостью определить абсолютный максимум функции .
С вычислительной точки зрения для выполнения алгоритма необходимо найти для всего изображения математическое ожидание и дисперсию . Далее при каждом значении определяются вероятности и с использованием (7.2) и (7.3) (или условия нормировки), а также математические ожидания классов и при помощи соотношений (7.4), (7.5). Найденные таким образом величины дают возможность определить значение .
Объем вычислений можно сократить, если выполнить некоторые преобразования формулы (7.7) для межклассовой дисперсии. Используя формулы (7.2)...(7.5), нетрудно получить соотношение для математических ожиданий:
![]() (7.11)
(7.11)
Выражая из (7.10) величину и подставляя ее в (7.11), окончательно находим:
 (7.12)
(7.12)
В соотношение (7.12), используемое в качестве рабочего, входят лишь две величины - вероятность и ненормированное математическое ожидание , что существенно уменьшает объем вычислений при автоматическом отыскании оптимального порога.
На рис. 7.2 приведены результаты эксперимента, иллюстрирующие описанный метод автоматической бинарной сегментации. На рис.7.2, а показан аэрофотоснимок участка земной поверхности "Поле", а на рис.7.2, б – результат его бинарной сегментации, выполненной на основе автоматического определения порога при помощи дискриминантного метода. Гистограмма распределения исходного изображения показана на рис.7.2, в, а дискриминантная функция , вычисленная по полученной гистограмме - на рис. 7.2, г. Сильная изрезанность гистограммы, порождающая большое количество минимумов, исключает возможность непосредственного определения единственного информационного минимума, разделяющего классы друг от друга. Функция же является существенно более гладкой и к тому же в данном случае унимодальной, что делает определение порога весьма простой задачей. Оптимальный порог, при котором получено сегментированное изображение, =100. Результаты показывают, что описанный метод нахождения порога, являясьразвитием гистограммного подхода, обладает сильным сглаживающим действием по отношению к изрезанности самой гистограммы.
Коснемся вопроса о пороговой сегментации нестационарных изображений. Если средняя яркость изменяется внутри кадра, то пороги сегментации должны быть также изменяющимися. Часто в этих случаях прибегают к разбиению кадра на отдельные области, в пределах которых изменениями средней яркости можно пренебречь. Это позволяет применять внутри отдельных областей принципы определения порогов, пригодные для работы со стационарными изображениями. На обработанном изображении наблюдаются в этом случае области, на которые разбито исходное изображение, отчетливо видны границы между областями. Это – существенный недостаток метода.
Более трудоемка, но и более эффективна процедура, использующая скользящее окно, при которой каждое новое положение рабочей области отличается от предыдущего только на один шаг по строке или по столбцу. Находимый на каждом шаге оптимальный порог относят к центральной точке текущей области. Таким образом, при этом методе порог изменяется в каждой точке кадра, причем эти изменения имеют характер, сопоставимый с характером нестационарности самого изображения. Процедура обработки, конечно, существенно усложняется.
Компромиссной является процедура, при которой вместо скользящего окна с единичным шагом применяют "прыгающее" окно, перемещающееся на каждом этапе обработки на несколько шагов. В "пропущенных" точках кадра порог может определяться с помощью интерполяции (часто применяют простейшую линейную интерполяцию) по его найденным значениям в ближайших точках.




Рис.7.2.Пример бинарной сегментации с автоматическим определением порога
Оценивая результативность пороговой сегментации по рис. 7.2, б, следует отметить, что данный метод дает возможность получить определенное представление о характере однородных областей, образующих наблюдаемый кадр. Вместе с темочевидно его принципиальное несовершенство, вызванное одноточечным характером принимаемых решений. Поэтому в последующих разделах обратимся к статистическим методам, позволяющим учитывать при сегментации геометрические свойства областей – размеры, конфигурацию и т.п. Отметим сразу же, что соответствующие геометрические характеристики задаются при этом своими вероятностными моделями и чаще всего в неявном виде.
Понятие сегментации, данное выше, является обобщенным понятием. Вообще говоря, изображение для наблюдателя часто представлено в виде некоторых однородных участков, отличающихся друг от друга различными характеристиками. Количество таких типов (или же классов) обычно невелико. Все изображение можно разбить на некоторое количество непересекающихся областей, каждая из которых является изображением одного из типов (классов). При анализе таких изображений целью любой системы является определение этих областей и указания их номера типа. Обработка изображения, позволяющая получить такую совокупность сведений о нем, и называется сегментацией . Иными словами, предполагается, что области изображения соответствуют реальным объектам или же их частям.
Однако существуют изображения, в которых вся картина разбита на области, не отличающиеся друг от друга ни по каким характеристикам. Тогда вся информация представляет в данном случае совокупность границ между этими областями. Простой пример: кирпичная или плиточная кладка.
Методы сегментации изображений делятся на два класса:
Автоматические, то есть такие методы, которые не требуют взаимодействия с пользователем;
Интерактивные или же ручные методы, использующие введенные пользовательские данные во время работы.
Задача сегментации изображения, как правило, применяется на некотором этапе обработки изображения, чтобы получить более точные и более удобные представления этого изображения для дальнейшей работы с ним.
Методов сегментации существует великое множество, и разные методы ориентированы на разные свойства разбиения изображения. Поэтому при выборе метода сегментации в той или иной задаче следует руководствоваться тем, какие же свойства разбиения действительно важны и какими свойствами обладает исходное изображение. Также необходимо решить, какая степень детализации, до которой доводится разделение на классы, оказывается приемлемой. Все зависит от каждой конкретной решаемой задачи. Например, при анализе микросхем задачей выделения объектов может быть выделение блоков микросхем и радиодеталей, а может быть обнаружение трещин на этих радиодеталях. Тогда логично, что в первом случае необходимо ограничиться более крупной детализацией.
Алгоритмы сегментации также делятся, как правило, на два класса:
1) основанные на базовом свойстве яркости: разрывности;
2) основанные на базовом свойстве яркости: однородности .
В первом случае изображение разбивается на области на основании некоторого изменения яркости, такого как, например, перепады яркости на изображении. Во втором случае используется разбиение изображение по критериям однородности областей. Примером первой категории может служить пороговая обработка или же пороговая классификация, а второй - выращивание областей, слияние и разбиение областей. О сегментации первого типа, а именно о пороговой обработке, и пойдет дальше речь.
Обычно пороговая сегментация изображений сводится к задаче сегментации полутоновых изображений. Действительно, выбор порога, как правило единственного, и сегментация на его основе и осуществляют переход от изображения в цветовом пространстве RGB к полутоновому, несмотря на то, что непосредственно предобработки перевода цветного изображения в полутоновое нет. Однако, иногда «цветная сегментация» все же применяется.
Предположим, что на RGB изображении необходимо выделить объекты, цвет которых лежит в определенном диапазоне. Задача сегментации в таком случае состоит в том, чтобы классифицировать каждый пиксель изображения в соответствии с тем, попадает ли его цвет в заданный диапазон или нет. Для этого в цветовом пространстве вводится мера сходства, как правило, евклидово расстояние . Евклидово расстояние между точками и определяется выражением
где, - RGB компоненты вектора, а, - вектора.
Идею применения такой обработки можно в общих чертах увидеть в разделе 2.6 пояснительной записки.
В данной работе в основном рассматривались и сегментировались изображения на основе одного порога, то есть осуществлялся переход к полутоновым изображениям. Причиной тому является тот факт, что задачи сегментации в цветовом пространстве RGB являются узконаправленными, и для каждого изображения в таком случае необходимо знать норму расстояния для каждой компоненты R,G и B, определить которые возможно лишь путем долгих экспериментов на конкретной предметной задаче.
Одной из главных целей компьютерного зрения при обработке изображений является интерпретация содержимого на изображении. Для этого необходимо качественно отделить фон от объектов. Сегментация разделяет изображение на составляющие части или объекты. Она отделяет объект от фона, чтобы можно было легко обрабатывать изображения и идентифицировать его содержимое. В данном случае выделение контуров на изображении является фундаментальным средством для качественной сегментации изображения. В данной статье предпринята попытка изучить производительность часто используемых алгоритмов выделения контуров для дальнейшей сегментации изображения, а также их сравнение при помощи программного средства MATLAB.
Сегментация изображений — огромный шаг для анализа изображений. Она разделяет изображение на составляющие части или объекты. Уровень детализации разделяемых областей зависит от решаемой задачи. К примеру, когда интересуемые объекты перестают сохранять целостность, разбиваются на более мелкие, составные части, процесс сегментации стоит прекратить. Алгоритмы сегментации изображений чаще всего базируются на разрыве и подобии значений на изображении. Подход разрывов яркости базируется на основе резких изменений значений интенсивности, подобие же — на разделение изображения на области, подобные согласно ряду заранее определенных критериев. Таким образом, выбор алгоритма сегментации изображения напрямую зависит от проблемы, которую необходимо решить. Обнаружение границ является частью сегментации изображений. Следовательно, эффективность решения многих задач обработки изображений и компьютерного зрения зависит от качества выделенных границ. Выделение их на изображении можно причислить к алгоритмам сегментации, которые базируются на разрывах яркости.
Процесс обнаружения точных разрывов яркости на изображении называется процессом выделение границ. Разрывы — это резкие изменения в группе пикселей, которые являются границами объектов. Классический алгоритм обнаружения границ задействует свертку изображения с помощью оператора, который основывается на чувствительности к большим перепадам яркости на изображении, а при проходе однородных участков возвращает нуль. Сейчас доступно огромное количество алгоритмов выделения контуров, но ни один из них не является универсальным. Каждый из существующих алгоритмов решает свой класс задач (т.е. качественно выделяет границы определенного типа). Для определения подходящего алгоритма выделения контуров необходимо учитывать такие параметры, как ориентация и структура контура, а также наличие и тип шума на изображении. Геометрия оператора устанавливает характерное направление, в котором он наиболее чувствителен к границам. Существующие операторы предназначены для поиска вертикальных, горизонтальных или диагональных границ. Выделение границ объектов — сложная задача в случае сильно зашумленного изображения, так как оператор чувствителен к перепадам яркости, и, следовательно, шум также будет считать некоторым объектом на изображении. Есть алгоритмы, позволяющие в значительной мере избавиться от шума, но в свою очередь, они в значительной мере повреждают границы изображения, искажая их. А так как большинство обрабатываемых изображений содержат в себе шум, шумоподавляющие алгоритмы пользуются большой популярностью, но это сказывается на качестве выделенных контуров.
Также при обнаружении контуров объектов существуют такие проблемы, как нахождение ложных контуров, расположение контуров, пропуск истинных контуров, помехи в виде шума, высокие затраты времени на вычисление и др. Следовательно, цель заключается в том, чтобы исследовать и сравнить множество обработанных изображений и проанализировать качество работы алгоритмов в различных условиях.
В данной статье предпринята попытка сделать обзор наиболее популярных алгоритмов выделения контуров для сегментации, а также реализация их в программной среде MATLAB. Второй раздел вводит фундаментальные определения, которые используются в литературе. Третий — предоставляет теоретический и математический и объясняет различные компьютерные подходы к выделению контуров. Раздел четыре предоставляет сравнительный анализ различных алгоритмов, сопровождая его изображениями. Пятый раздел содержит обзор полученных результатов и заключение.
Сегментация изображения — это процесс разделения цифрового изображения на множество областей или наборов пикселей. Фактически, это разделение на различные объекты, которые имеют одинаковую текстуру или цвет. Результатом сегментации является набор областей, покрывающих вместе все изображение, и набор контуров, извлеченных из изображения. Все пиксели из одной области подобны по некоторым характеристикам, таким как цвет, текстура или интенсивность. Смежные области отличаются друг от друга этими же характеристиками. Различные подходы нахождения границ между областями базируются на неоднородностях уровней интенсивности яркости. Таки образом выбор метода сегментации изображения зависит от проблемы, которую необходимо решить.
Методы, основанные на областях, базируются на непрерывности. Данные алгоритмы делят все изображение на подобласти в зависимости от некоторых правил, к примеру, все пиксели данной группы должны иметь определенное значение серого цвета. Эти алгоритмы полагаются на общие шаблоны интенсивности значений в кластерах соседних пикселей.
Пороговая сегментация является простейшим видом сегментации. На ее основе области могут быть классифицированы по базовому диапазону значений, которые зависят от интенсивности пикселей изображения. Пороговая обработка преобразовывает входное изображение в бинарное.
Методы сегментации, основанные на обнаружении областей, находят непосредственно резкие изменения значений интенсивности. Такие методы называются граничными методами. Обнаружение границ — фундаментальная проблема при анализе изображений. Техники выделения границ обычно используются для нахождения неоднородностей на полутоновом изображении. Обнаружение разрывов на полутоном изображении — наиболее важный подход при выделении границ.
Границы объектов на изображении в значительной степени уменьшают количество данных, которые необходимо обработать, и в то же время сохраняет важную информацию об объектах на изображении, их форму, размер, количество. Главной особенностью техники обнаружения границ является возможность извлечь точную линию с хорошей ориентацией. В литературе описано множество алгоритмов, которые позволяют обнаруживать границы объектов, но нигде нет описания того, как оценивать результаты обработки. Результаты оцениваются сугубо индивидуально и зависят от области их применения.
Обнаружение границ — фундаментальный инструмент для сегментации изображения. Такие алгоритмы преобразуют входное изображение в изображение с контурами объектов, преимущественно в серых тонах. В обработке изображений, особенно в системах компьютерного зрения, с помощью выделения контура рассматривают важные изменения уровня яркости на изображении, физические и геометрические параметры объекта на сцене. Это фундаментальный процесс, который обрисовывает в общих чертах объекты, получая тем самым некоторые знания об изображении. Обнаружение границ является самым популярным подходом для обнаружения значительных неоднородностей.
Граница является местным изменением яркости на изображении. Они, как правило, проходят по краю между двумя областями. С помощью границ можно получить базовые знания об изображении. Функции их получения используются передовыми алгоритмами компьютерного зрения и таких областях, как медицинская обработка изображений, биометрия и тому подобные. Обнаружение границ — активная область исследований, так как он облегчает высокоуровневый анализ изображений. На полутоновых изображениях существует три вида разрывов: точка, линия и граница. Для обнаружения всех трех видов неоднородностей могут быть использованы пространственные маски.
В технической литературе приведено и описано большое количество алгоритмов выделения контуров и границ. В данной работе рассмотрены наиболее популярные методы. К ним относятся: оператор Робертса, Собеля, Превитта, Кирша, Робинсона, алгоритм Канни и LoG-алгоритм.
Оператор выделения границ Робертса введен Лоуренсом Робертсом в 1964 году. Он выполняет простые и быстрые вычисления двумерного пространственного измерения на изображении. Этот метод подчеркивает области высокой пространственной частоты, которые зачастую соответствуют краям. На вход оператора подается полутоновое изображение. Значение пикселей выходного изображения в каждой точке предполагает некую величину пространственного градиента входного изображения в этой же точке.
Оператор Собеля введен Собелем в 1970 году. Данный метод обнаружения границ использует приближение к производной. Это позволяет обнаруживать край в тех местах, где градиент самый высокий. Данный способ обнаруживает количество градиентов на изображении, тем самым выделяя области с высокой пространственной частотой, которые соответствуют границам. В целом это привело к нахождению предполагаемой абсолютной величине градиента в каждой точке входного изображения. Данный оператор состоит из двух матриц, размером 3×3. Вторая матрица отличается от первой только тем, что повернута на 90 градусов. Это очень похоже на оператор Робертса.

Обнаружение границ данным методом вычислительно гораздо проще, чем методом Собеля, но приводит к большей зашумленности результирующего изображения.
Обнаружение границ данным оператором предложено Превиттом в 1970 году. Правильным направлением в данном алгоритме была оценка величины и ориентация границы. Даже при том, что выделение границ является весьма трудоемкой задачей, такой подход дает весьма неплохие результаты. Данный алгоритм базируется на использовании масок размером 3 на 3, которые учитывают 8 возможных направлений, но прямые направления дают наилучшие результаты. Все маски свертки рассчитаны.

Обнаружение границ этим методом было введено Киршем в 1971 году. Алгоритм основан на использовании всего одной маски, которую вращают по восьми главным направлениям: север, северо-запад, запад, юго-запад, юг, юго-восток, восток и северо-восток. Маски имеют следующий вид:

Величина границы определена как максимальное значение, найденное с помощью маски. Определенное маской направление выдает максимальную величину. Например, маска k 0 соответствует вертикальной границе, а маска k 5 — диагональной. Можно также заметить, что последние четыре маски фактически такие же, как и первые, они являются зеркальным отражением относительно центральной оси матрицы.
Метод Робинсона, введенное в 1977, подобен методу Кирша, но является более простым в реализации в силу использования коэффициентов 0, 1 и 2. Маски данного оператора симметричны относительно центральной оси, заполненной нулями. Достаточно получить результат от обработки первых четырех масок, остальные же можно получить, инвертируя первые.

Максимальное значение, полученное после применения всех четырех масок к пикселю и его окружению считается величиной градиента, а угол градиента можно аппроксимировать как угол линий нулей в маске, которые дают максимальный отклик.
Marr-Hildreth (1980) метод — метод обнаружения границ в цифровых изображениях, который обнаруживает непрерывные кривые везде, где заметны быстрые и резкие изменения яркости группы пикселей. Это довольно простой метод, работает он с помощью свертки изображения с LoG-функцией или как быстрая аппроксимация с DoG. Нули в обработанном результате соответствуют контурам. Алгоритм граничного детектора состоит из следующих шагов:
Алгоритм выделения контуров Лаплассиан Гауссиана был предложен в 1982 году. Данный алгоритм является второй производной, определенной как:

Он осуществляется в два шага. На первом шаге он сглаживает изображение, а затем вычисляет функцию Лапласса, что приводит к образованию двойных контуров. Определение контуров сводится к нахождению нулей на пересечении двойных границ. Компьютерная реализация функции Лапласса обычно осуществляется через следующую маску:

Лаплассиан обычно использует нахождение пикселя на темной или светлой стороне границы.
Детектор границ Канни является одной из самых популярных алгоритмов обнаружения контуров. Впервые он был предложен Джоном Канни в магистерской диссертации в 1983 году, и до сих пор является лучше многих алгоритмов, разработанных позднее. Важным шагом в данном алгоритме является устранение шума на контурах, который в значительной мере может повлиять на результат, при этом необходимо максимально сохранить границы. Для этого необходим тщательный подбор порогового значения при обработке данным методом.
Алгоритм:
В отличии от операторов Робертса и Собеля, алгоритм Канни не очень восприимчив к шуму на изображении.
В данном разделе представлены результаты работы описанных ранее алгоритмов обнаружения границ объектов на изображении.
Все описанные алгоритмы были реализованы в программной среде MATLAB R2009a и протестированы на фотографии университета. Цель эксперимента заключается в получении обработанного изображения с идеально выделенными контурами. Оригинальное изображение и результаты его обработки представлены на рисунке 1.

Рисунок 1 — Оригинальное изображение и результат работы различных алгоритмов выдеоения контуров
При анализе полученных результатов были выявлены следующие закономерности: операторы Робертса, Собеля и Превитта дают очень различные результаты. Marr-Hildreth, LoG и Канни практически одинаково обнаружили контуры объекта, Кирш и Робинсон дали такой же результат. Но наблюдая полученные результаты можно сделать вывод, что алгоритм Канни справляется на порядок лучше других.
Обработка изображений — быстро развивающаяся область в дисциплине компьютерного зрения. Ее рост основывается на высоких достижениях в цифровой обработке изображений, развитию компьютерных процессоров и устройств хранения информации.
В данной статье была предпринята попытка изучить на практике методы выделения контуров объектов, основанных на разрывах яркости полутонового изображения. Исследование относительной производительности каждого из приведенных в данной статье методов осуществлялся с помощью программного средства MATLAB. Анализ результатов обработки изображения показал, что такие методы, как Marr-Hildreth, LoG и Канни дают практически одинаковые результаты. Но все же при обработке данного тестового изображения наилучшие результаты можно наблюдать после работы алгоритма Канни, хотя при других условиях лучшим может оказаться другой метод.
Даже учитывая тот факт, что вопрос обнаружения границ на изображении достаточно хорошо осветлен в современной технической литературе, он все же до сих пор остается достаточно трудоемкой задачей, так как качественное выделение границ всегда зависит от множества влияющих на результат факторов.
1. Canny J.F. (1983) Finding edges and lines in images, Master"s thesis, MIT. AI Lab. TR-720.
2. Canny J.F. (1986) A computational approach to edge detection , IEEE Transaction on Pattern Analysis and Machine Intelligence, 8. — P. 679-714.
3. Courtney P, Thacker N.A. (2001) Performance Characterization in Computer Vision: The Role of Statistics in Testing and Design , Chapter in: Imaging and Vision Systems: Theory, Assessment and Applications , Jacques Blanc-Talon and Dan Popescu (Eds.), NOVA Science Books.
4. Hanzi Wang (2004) Robust Statistics for Computer Vision: Model Fitting, Image Segmentation and Visual Motion Analysis, Ph.D thesis, Monash University, Australia.
5. Huber P.J. (1981) Robust Statistics, Wiley New York.
6. Kirsch R. (1971) Computer determination of the constituent structure of biological images , Computers and Biomedical Research, 4. — P. 315–328.
7. Lakshmi S, Sankaranarayanan V. (2010) A Study of edge detection techniques for segmentation computing approaches , Computer Aided Soft Computing Techniques for Imaging and Biomedical Applications. — P. 35-41.
8. Lee K., Meer P. (1998) Robust Adaptive Segmentation of Range Images , IEEE Trans. Pattern Analysis and Machine Intelligence, 20(2). — P. 200-205.
9. Marr D, Hildreth E. (1980) Theory of edge detection , Proc. Royal Society of London, B, 207. — P. 187–217.
10. Marr D. (1982) Vision, Freeman Publishers.
11. Marr P., Doron Mintz. (1991) Robust Regression for Computer Vision: A Review , International Journal of Computer Vision, 6(1). — P. 59-70.
12. Orlando J. Tobias, Rui Seara (2002) Image Segmentation by Histogram Thresholding Using Fuzzy Sets , IEEE Transactions on Image Processing, Vol.11, No.12. — P. 1457-1465.
13. Punam Thakare (2011) A Study of Image Segmentation and Edge Detection Techniques , International Journal on Computer Science and Engineering, Vol 3, No.2. — P. 899-904.
14. Rafael C., Gonzalez, Richard E. Woods, Steven L. Eddins (2004) Digital Image Processing Using MATLAB, Pearson Education Ptd. Ltd, Singapore.
15. Ramadevi Y. (2010) Segmentation and object recognition using edge detection techniques , International Journal of Computer Science and Information Technology, Vol 2, No.6. — P. 153-161.
16. Roberts L. (1965) Machine Perception of 3-D Solids , Optical and Electro-optical Information Processing, MIT Press.
17. Robinson G. (1977) Edge detection by compass gradient masks , Computer graphics and image processing, 6. — P. 492-501.
18. Rousseeuw P. J., Leroy A. (1987) Robust Regression and outlier detection, John Wiley & Sons, New York.
19. Senthilkumaran N., Rajesh R. (2009) Edge Detection Techniques for Image Segmentation — A Survey of Soft Computing Approaches , International Journal of Recent Trends in Engineering, Vol. 1, No. 2. — P. 250-254.
20. Sowmya B., Sheelarani B. (2009) Colour Image Segmentation Using Soft Computing Techniques , International Journal of Soft Computing Applications, Issue 4. — P. 69-80.
21. Umesh Sehgal (2011) Edge detection techniques in digital image processing using Fuzzy Logic , International Journal of Research in IT and Management, Vol.1, Issue 3. — P. 61-66.
22. Yu, X, Bui, T.D. & et al. (1994) Robust Estimation for Range Image Segmentation and Reconstruction , IEEE trans. Pattern Analysis and Machine Intelligence, 16 (5). — P. 530-538.
Cегментация означает выделение областей однородных по какому-либо критерию, например по яркости. Математическая формулировка задачи сегментации может иметь следующий вид .
Пусть
-функция
яркости анализируемого изображения;
X
– конечное
подмножество плоскости на котором
определена
 ;
; - разбиение
X
на
K
непустых
связных подмножеств
- разбиение
X
на
K
непустых
связных подмножеств
 LP
–
предикат,
определенный на множестве S
и принимающий
истинные значения тогда и только тогда,
когда любая пара точек из каждого
подмножества
LP
–
предикат,
определенный на множестве S
и принимающий
истинные значения тогда и только тогда,
когда любая пара точек из каждого
подмножества
 удовлетворяет критерию однородности.
удовлетворяет критерию однородности.
Сегментацией
изображения
 по предикату
LP
называется
разбиение
по предикату
LP
называется
разбиение

 ,
удовлетворяющее условиям:
,
удовлетворяющее условиям:
а)
 ;
;
б)
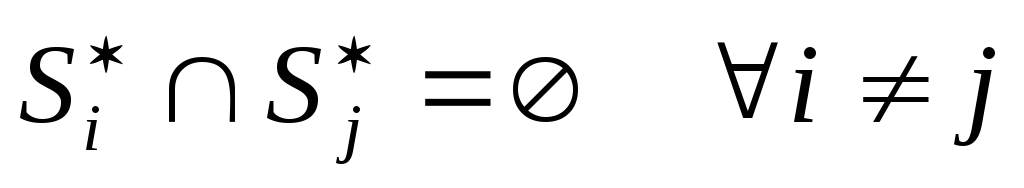 ;
;
в)
 ;
;
г) смежные области.
Условия а) и б) означают, что каждая точка изображения должна быть единственным образом отнесена к некоторой области, в) определяет тип однородности получаемых областей и, наконец, г) выражает свойство “максимальности” областей разбиения.
Предикат LP называется предикатом однородности и может быть записан в виде:
 (1)
(1)
где
 -отношение
эквивалентности;
-отношение
эквивалентности;
 - произвольные точки из
- произвольные точки из
 .Таким образом,
сегментацию можно рассматривать как
оператор вида:
.Таким образом,
сегментацию можно рассматривать как
оператор вида:
где
 -функции,
определяющие исходное и сегментированное
изображение соответственно;
-функции,
определяющие исходное и сегментированное
изображение соответственно;
 -метка i-
й
области.
-метка i-
й
области.
Существуют
два общих подхода к решению задачи
сегментации
, которые
базируются на альтернативных
методологических концепциях. Первый
подход основан на идее “разрывности”
свойств
точек изображения при переходе от одной
области к другой. Этот подход сводит
задачу сегментации к задаче выделения
границ областей. Успешное решение
последней позволяет, вообще говоря,
идентифицировать и сами области, и их
границы. Второй подход реализует
стремление выделить точки изображения,
однородные по своим локальным свойствам,
и объединить их в область, которой позже
будет присвоено имя или смысловая метка.
В литературе первый подход называют
сегментацией
путем выделения границ областей
,
а второй – сегментацией
путем разметки точек области
.
Данное выше математическое определение
задачи позволяет характеризовать эти
подходы в терминах предиката однородности
LP
.
В первом
случае в качестве LP
должен
выступать предикат, принимающий истинные
значение на граничных точках областей
и ложные значения на внутренних точках.
Однако можно отметить существенное
ограничение этого подхода, состоящее
в том, что разбиение
 является
здесь двухэлементным множеством. В
практическом плане это означает, что
алгоритмы выделения границ не позволяют
идентифицировать разными метками разные
области.
является
здесь двухэлементным множеством. В
практическом плане это означает, что
алгоритмы выделения границ не позволяют
идентифицировать разными метками разные
области.
Для второго подхода предикат LP может иметь вид, определяемый соотношением (5.1). Указанные выше подходы порождают конкретные методы и алгоритмы решения задачи сегментации.
Пороговая обработка изображения означает преобразование его функции яркости оператором вида

где
s(x,y)
– сегментированное
изображение;
K
–
число
областей сегментации;
 - метки сегментированных областей;
- метки сегментированных областей;
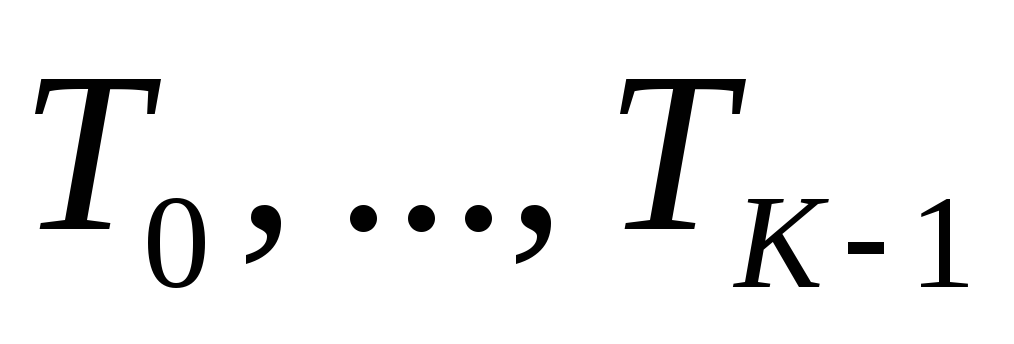 - величины порогов, упорядоченные так,
что
- величины порогов, упорядоченные так,
что
 .
.
В частном случае при K= 2 пороговая обработка предусматривает использование единственного порога T . При назначении порогов применяют, как правило, гистограмму значений фунции яркости изображения.
Алгоритм сегментации на основе пороговой обработки на псевдокоде
Вход: mtrIntens – исходная матрица полутонового изображения;
l, r – пороги по гистограмме
Выход: mtrIntensNew – матрица сегментированного изображения
for i:=0 to l-1 do
for i:=l to r do
for i:=r+1 to 255 do
LUT[i]=255;
for i:=1 to 100 do
for j:=1 to 210 do
mtrIntensNew:=LUT]
Вредоносное ПО (malware) - это назойливые или опасные программы,...

Лучшие программы для восстановления данных с любых носителей информации....

Здравствуйте.Одна из самых распространенных причин, по которым тормозит...