Вредоносное ПО (malware) - это назойливые или опасные программы,...


Обновлено — 2017-02-14
Локальная сеть с доступом в интернет. Если у вас дома несколько компьютеров и все ваши домочадцы постоянно работают за ними, а выход в Интернет только у одного из них, то вы наверняка уже не раз задавались вопросом: — Как подключить все эти компьютеры к скоростному Интернету ADSL через один модем?
Вот об этом мы сейчас и поговорим. Причем, не обязательно все компьютеры настольные. Это можно сделать и с ноутбуками. Все настройки я буду описывать для Windows XP. Хотя тоже самое можно проделать и для других систем. Разница только в доступе к настройкам сетевой карты. Во всех операционных системах настройки сетевой карты спрятаны по-разному.
Разница только в пути к ним, т.к. у разных систем разные панели управления. Какими бы ни были хорошими и навороченными новые операционные системы (Vista и Windows 7), но я предпочитаю Windows XP. Её настройки (особенно для локальной сети) самые гибкие и простые.
У меня дома три компьютера, и все постоянно заняты. И долгое время выход в Интернет был только на одном компьютере, что очень неудобно. Но вот наступил момент, когда мы поняли – пора что-то делать. Собрали маленький домашний совет, и решили создать свою маленькую локальную сеть с общим доступом в Интернет.
Купили коммутатор на пять портов,
и три сетевых кабеля: один — 3-х метровый и 2 по10 метров.

Сетевые карты во всех трёх компьютерах встроенные в материнскую плату, поэтому мы купили только одну — для подключения модема.

Модем у нас уже имелся в наличии.

В общем, всё обошлось «малой кровью» — чуть больше 700 рублей.


Потом взялись за настройку локальной сети.








Описание можно не писать, а имя должно быть понятным для Вас. Лучше меняйте его на этом шаге. Чтобы всё работало без проблем, все имена должны быть прописаны английскими буквами, а большими или маленькими – значения не имеет.
У нас сначала компьютер назывался STELLA , поэтому он пишет текущее имя STELLA , а сейчас мы его переименуем в SERVER . И опять жмем кнопку «Далее «. В следующем окне необходимо указать рабочую группу.

Имя рабочей группы можете оставить как есть, а можете и изменить на то, которое Вам нравиться. Это тоже ни на что не влияет. Жмем кнопку «Далее «.

На этой странице лучше всё оставить как есть.
На следующей странице Вы увидите все те данные, которые внесли для настройки своей сети. Если Вас что-то не устраивает, то можете вернуться по кнопке «Назад » и изменить то, что Вам нужно. Если всё устраивает, то жмете кнопку «Далее ».

В этом окне лучше установить точку на «Просто завершить работу мастера … ».

Далее жмем кнопку «Готово » и система предложит Вам перезагрузиться. Следуйте этому совету. Точно таким же образом мы настроили сетевые карты на других двух компьютерах. Единственное отличие только в другом имени, а имя группы у всех должно быть одним (т.е. одинаковым).

На другом компьютере, как Вы видите у нас название значка не изменено, так как других значков нет, и его ни с чем не перепутаешь. Сетевая карта ведь одна.
В «Протокол Интернета (TCP / IP ) » для второго компьютера прописываем:
IP -адрес: 192.168.0.2
Основной шлюз: 198.162.0.1
Предпочитаемый DNS -сервер: 192.168.0.1
Альтернативный DNS -сервер: ничего не пишем

В «Протокол Интернета (TCP / IP ) » для третьего компьютера прописываем:
IP -адрес: 198.162.0.3
Маска подсети: 255.255.255.0
Основной шлюз: 198.162.0.1
Предпочитаемый DNS -сервер: 192.168.0.1
Альтернативный DNS -сервер: ничего не пишем

Всё тоже самое, что и на втором, только у IP -адреса последняя цифра 3 .
Сеть у нас настроена. Теперь настраиваем сетевую карту, к которой подключен модем (если у Вас уже подключен модем и настроен Интернет, тогда эту часть статьи можете пропустить).
Идем опять к первому компьютеру, который назвали «Сервер ». Заходим в – Пуск – Панель управления – Сетевые подключения . Щелкаем правой кнопкой мыши по значку сетевой карты «Интернет » и в выпадающем меню выбираем «Свойства ».

Откроется окно «Интернет – свойства ». В нём на вкладке «Общие » выбираем в маленьком окошке «Компоненты, используемые этим подключением: » запись «Протокол Интернета (TCP / IP ) » и открываем его либо двойным щелчком мыши либо кнопкой «Свойства ».

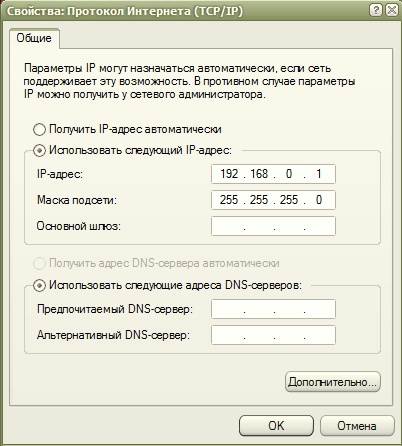
В новом открывшемся окне «Свойства: Протокол Интернета (TCP / IP ) » устанавливаем точку на записи «Использовать следующий IP -адрес: » и прописываем:
IP -адрес: 192.168.1.26
Маска подсети: 255.255.255.0
Основной шлюз: 192.168.1.1
(Эти цифры у Вас могут быть другими. Их можно узнать по телефону техподдержки у Вашего провайдера Интернета).
И нажимаем кнопку «ОК ».

Попадаем опять в окно «Интернет – свойства ». Переходим на вкладку «Дополнительно ».

Устанавливаем в нем галочку «Разрешить другим пользователям сети использовать подключение к Интернету данного компьютера». И снимите галочку с «Разрешить другим пользователям сети управлять общим доступом к подключению к Интернету ». Жмем кнопку «ОК » и перезагружаем все компьютеры. Вот и всё. Теперь у нас есть сеть с подключением всех компьютеров к Интернету.
На других компьютерах (Клиентах) Вам нужно только запустить Ваш браузер (Оперу или то, что у Вас установлено).
Вот схема подключения наших компьютеров:

Обязательно необходимо на всех компьютерах установить антивирусник, тем более он у Вас сможет регулярно обновляться. Наслаждайтесь преимуществом локальной сети.
Настройки ничем не отличается от подключения, которое мы рассмотрели выше. Единственное отличие – это отсутствие коммутатора, т.к. мы просто соединяем один компьютер с другим при помощи одного сетевого кабеля.
Кстати, из своего опыта могу сказать, что кабель можете взять тот же, что и для локальной сети, а не витую пару. Для двух компьютеров это неважно. А вот при подключении витой пары к коммутатору у вас сеть работать не будет.
Вот мы и рассмотрели вопросы:
В ближайшее время я расскажу вам, , и как .
Видеоролик: Настройка локальной сети в Windows 7
Видеролик Как снять пароль доступа к сети, папкам и принтерам
«Нет ничего более постоянного, чем временное...»
житейское
Определимся с отправными моментами: небольшая компания, пускай примерно 15-50 сотрудников. Как правило – квалифицированного сетевого специалиста нет. И скорее всего именно "выделенного" для работы с сетью, администратора сети по штату. Если есть – мастер на все руки, причем часто вынужден заниматься каким-то "срочным" делом вроде установки Windows или драйверов на какой-нибудь компьютер, вместо работы с сетью. Вместе с другими "компьютерщиками"(если они есть). Сеть работает? Пускай через пень колоду, ну и ладно, чуть позже займется (займемся).
Давайте условимся – свой специалист, все-таки необходим. И ему надо платить деньги, причем – хорошие деньги (ужас какой, да? вот новость-то для многих директоров). Попробую в этой статье (возможно, с продолжением) выступить в роли администратора сети такой небольшой фирмы.
Исходные данные
Итак, строим сеть сами. Почему нет? Есть много аргументов "против" "самопальщины", и все они верны (если, конечно, это не откровенная "лапша" от потенциального подрядчика). Но, все-таки, можно и самому. Аргументов "за" тоже хватает. Не будем здесь их приводить – считаем, что решили делать сами.
Однако, надо понимать, что работу должен выполнять специалист (или несколько). Нельзя тренировать («хоть плохонький, но свой») и растить своего специалиста таким методом. Своего можно отдать в практику человеку, выполняющему работы (бурение дыр перфоратором в стенах и крепление кабель-канала не будем брать во внимание – это должен уметь любой мужик).
Еще один фактор, добавим так сказать, "перчику"– наша фирма, помимо офиса, имеет магазин и склад, которые достаточно удалены.
Мы будем делать не новомодные радио-, Wi-Fi и прочие сети, а недорогую, но качественную кабельную сеть традиционного проводного типа для повседневной работы фирмы. Для работы, а не для серфинга с ноутбука новостных и/или порно-сайтов с гостиничного дивана. К этим вопросам мы, возможно, вернемся в продолжении (не к гостинице и иже с ней, разумеется, а к современным технологиям).
Последнее, и, также, очень важное: деньги считаем, но не жадничаем.
План
В самом начале надо обязательно сделать одну очень простую, но очень важную вещь – взять несколько листков бумаги, карандаш и сесть за черновой бизнес-план. Очень важно более-менее четко "взять на карандаш"все ключевые слова, которые придут на ум от вопроса «что я хочу от сети». Эти позиции набросать на первом листе. На втором – их сгруппировать по раздельным категориям. Например – категория «сервисы». Какие именно сервисы мы хотим получить от сети, и какого качества? Что нам необходимо? File-, ftp-, print-, internet-сервис?
Казалось бы, вроде все ясно, зачем писать, рисовать? Но, если не взять все на карандаш – потом будет хуже. К примеру, окажется, что надо идти к директору и/или в бухгалтерию: «Извините, мы вот тут не ту железку купили, да и не за 100 у.е. надо, а за 500...».
Теперь можно передохнув добавить что надо, выбросить излишества. И всё это отложить как минимум на денёк. Далее черновик можно перенести на третий лист. С "окончательными"дополнениями и исправлениями. Почему кавычки – вы сами понимаете, это не последний листок, и далеко не последние «зарисовки».
Сервисы – сервисами, однако, база – это СКС, то есть, структурированная кабельная система. Давайте будем стараться не бежать сильно впереди лошади.
Обычно есть два варианта – офис "с нуля"и офис «готов». Первый случай – голые стены и потолок, ремонт – наши, и это хорошо. Второй вариант - «готово». Т.е. – начинаем внешнюю прокладку СКС. Но, начнем не с этого, пока.
Электричество
Важный этап, ведь не дай Бог "полетит" не просто один-два рядовых компьютера, может "полететь" всё. Хорошо, считаем, что у нас в офисе с силовой сетью всё в порядке. Здесь только один важный момент – источники бесперебойного питания (ИБП). Они необходимы . Поверьте. Дизель-генератор, конечно, хорош, но не во всех случаях обязателен, а вот жалеть денег на установку ИБП на каждый сервер или коммуникационный шкаф просто глупо. Впрочем, к вопросу об ИБП мы вернемся в свое время.
СКС и базовое активное оборудование
Структурированная кабельная система (СКС) – один из краеугольных камней. СКС должна быть правильно спроектирована и построена. Разделим вопрос на пункты:
Здесь очень пригодится план помещений, с четко отмеченными местами сотрудников. Надо иметь ввиду – неплохо еще и силовые розетки отметить. Далее - по порядку, начнем с шкафа.
Коммуникационный шкаф : находим удобное место для установки шкафа с оборудованием. Важно найти оптимальное расстояние до рабочих станций, с целью уменьшения расходов на витую пару, кабель-канал и прочую «мелочь». Факторов много: ограничение длины линии до 100 метров (вернее, 90 метров, по классической формуле 90+5+5); планировка офиса (в каком месте удобно поставить или повесить шкаф, удобно ли проходить стены при протяжке кабеля, не будет ли охлаждение давить на уши клиентам или сотрудникам и т.д.); собственно, конструктив шкафа (напольный, настенный, его высота в U, количество оборудования, которое надо в него установить, будет ли блок охлаждения).
Шкафы существуют самые разнообразные, надо внимательно посмотреть цены и качество предполагаемой покупки, не забыть сделать запас по ёмкости(!) в тех самых U. Обязательно – наличие как минимум одной полки. Впрочем, в некоторых местах вполне можно обойтись и настенными кронштейнами, для закрепления оборудования. Но это уже специфика. Будем считать, что для офиса мы выбрали 12-14-высотный шкаф, со стеклянной дверью. Немного забегая вперед, надо упомянуть что будет устанавливаться внутрь:
Полка : пригодится всегда, даже если будет пустовать (сомневаюсь) – ее можно снять. Не стоит жалеть 10-20 долларов, когда придётся "вдруг"поставить в шкаф устройство-другое, вспомните эти строки.
Коммутатор (switch): 24 порта по нижнему пределу сотрудников фирмы в офисе – пускай будет 10-20 человек в офисе (и не забываем о серверах и другом сетевом оборудовании). Впрочем, если будет бо льшая плотность рабочих мест, никаких проблем добавить необходимое количество коммутаторов и прочего соответствующего оборудования не будет.
Распределительная панель (patch-панель) : 24 порта, все аналогично с коммутатором. Именно на патч-панель и будут сводиться все линии от рабочих станций и серверов.
Панель (блок) силовых розеток : по количеству подключаемого оборудования в шкафу, плюс – запас 1-2 розетки на панели. Здесь нас вполне может ожидать "засада" если придется подключать блоки питания – может не хватить (вспоминаем о 99,9% рынка, заполненных сетевыми фильтрами с плотно-косо посаженными розетками).
ИБП : можно поставить дешёвый простенький вариант (вот когда пригодится полка, но можно и на пол шкафа), можно и 19” ИБП, предназначенный для установки в шкаф.
Итак, посмотрев предлагаемую на рынке продукцию, считаем, что со шкафом определились: 14-высотный (14 U). Например, Molex MODBOX II 14U:
Возможность применения в шкафу 19-дюймового вентилятора 1U
Стандартная комплектация шкафа:
Легкий стальной профиль обеспечивает шкафу большую жесткость и прочность
Эстетичная стеклянная дверь с замком
Дверь универсальной конструкции с возможностью перевешивания (левая, правая)
19-тидюймовая рама с регуляцией глубины
Заземление всех элементов шкафа
Отверстия для ввода кабеля снабжены защитной щеткой для защиты от проникновения пыли в шкаф
Коммутатор. Его выбор – более сложный вопрос. Совсем дешёвые коммутаторы не хочется рассматривать. Остаются устройства подороже (и очень подороже), но все равно придется выбирать из двух типов: неуправляемые и управляемые.
Остановим взгляд на следующих двух устройствах: ZyXEL Dimension ES-1024 и ES-2024:

Технические характеристики :
24-портовый коммутатор Fast Ethernet
Соответствие стандартам IEEE 802.3, 802.3u и 802.3x
Порты Ethernet RJ-45 с автоматическим выбором скорости 10/100 Мбит/с
Автоматическое определение подключения перекрестного кабеля на всех портах Ethernet RJ-45 10/100 Мбит/с
Поддержка управления потоком Back-Pressure-Base на полудуплексных портах
Поддержка управления потоком Pause-Frame-Base на полнодуплексных портах
Поддержка коммутации с промежуточным хранением
Поддержка автоматического определения адресов
Максимальная скорость пересылки по проводной сети
Встроенная таблица MAC-адресов (объем 8K MAC-адресов)
Светодиодные индикаторы питания, LK/ACT и FD/COL

Технические характеристики :
24 порта RJ-45 с автоматическим выбором скорости 10/100 Ethernet и автоматическим определением подключения перекрестного кабеля
2 портами 10/100/1000 Ethernet
2 слота стандарта mini-GBIC, совмещённых с портами
8,8 Гбит/сек неблокируемая коммутационная шина
Поддержка протоколов IEEE 802.3u, 802.3ab, 802.3z, 802.3x, 802.1D, 802.1w, 802.1p
Таблица MAC адресов 10Кб
Поддержка VLAN: Port-based и 802.1Q
Возможность ограничения скорости на порту
64 статических VLAN и до 2Кб динамических VLAN
Фильтрация MAC – адресов
Поддержка ZyXEL iStacking™, до 8 коммутаторов (в будущем до 24) управляемых по одному адресу IP
Управление по RS-232 и по WEB-интерфейсу
Telnet CLI
SNMP V2c(RFC 1213, 1493, 1643, 1757, 2647)
Управление по IP: статический IP или DHCP-клиент
Обновление микропрограммы по FTP
Обновление и сохранение системной конфигурации
Стандартное 19-дюймовое исполнение для монтажа в стойку
Как видим – разница есть, и весьма серьезная. Как есть разница в цене – приблизительно 100 и 450 долларов. Но, если первый коммутатор приличный, но "тупой"ящик, то второй – в каком-то смысле интеллектуальный, с гораздо большей функциональностью и управляемый, с потенциально сильными сторонами. Выбираем второй вариант. Мы ведь хотим построить хорошую сеть?
Кстати, именно сейчас вполне пора задаться вопросом, почему, собственно, строим сеть «сотку»? Нынче в каждом втором компьютере не просто гигабитный сетевой интерфейс, а два гигабитных?
Вот это и есть тот случай, где можно смело экономить. Дело в том, что для работы офиса 100-мегабитной сети более чем достаточно. Если к тому же еще и коммутатор приличный! Да, а на два гигабитных интерфейса выбранного коммутатора – смело "садим", например, два сервера. Вот им, серверам, это как раз только на пользу.
Конечно, можно взять что-то вроде ZyXEL GS-2024 и посадить всех на гигабитный канал, но это как раз случай неразумной траты денег, ведь его стоимость порядка 1300 долларов, и за такие деньги мы можем купить полностью весь шкаф с более укомплектованной начинкой.

Соответствие требованиям категории 5е. Система компенсации реализована непосредственно на печатной плате. Применение коннекторов типа КАТТ ускоряет и упрощает монтаж кабеля. Выделенное место для маркировки каналов. Панель покрыта порошковым лаком. Все необходимые крепежные и маркировочные элементы поставляются в комплекте.
ИБП. Здесь много вариантов, как уже говорилось, можно поставить любой дешевый, можно дороже, можно 19” rack-вариант – будет и вовсе красота. Кто не знает фирму APC? Можно посмотреть например такой ИБП:
APC Smart-UPS SC 1500VA 230V - 2U Rackmount/Tower
Или, вот такой:
IPPON Smart Winner 1500
Не углубляясь в характеристики, заметим, что многие устройства комплектуются по запросу направляющими для установки ИБП в 19" стойку. Также, есть возможность укомплектовать, по желанию, модулем SNMP для мониторинга и управления ИБП по компьютерной сети. Конечно, это будет стоить денег, но может оказаться очень удобно. Остановим свой выбор на IPPON. Надо заметить, что поддержкой SNMP могут комплектоваться модели 1500, 2000 и 3000, а 750 и 1000 – нет.
Блок силовых розеток:
Molex Modbox 25.D0160
Без особых комментариев – может быть, можно найти что-нибудь и дешевле, проще. Но десяток "удушенных енотов" погоду не сделают.
Осталось не забыть принять решение, необходим ли вентиляторный блок в шкаф? Дорогое удовольствие, особенно в паре с блоком терморегулятора. Однако, отнесем это уже к конкретике места/офиса.
Molex Modbox RAA-00145
Со шкафом более-менее разобрались, остались всякие «мелочи», без учета которых потом будут досадные задержки:
Фактически, мы добрались до самой СКС. Очень важная "деталь"- кабель, которым и будет делаться разводка СКС. Да, опять призыв не экономить. Хорошая витая пара – это хорошее вложение. Берем Molex, неэкранированный кабель UTP PowerCat 5е.

К абонентским розеткам, мы, конечно же, придем, а дальше? Дальше – купить необходимое количество патч-кордов для подключения рабочих станций. Естественно, надо продумать длину, посмотреть по упоминавшемуся плану офиса. Но это ещё не всё. Необходим еще и strainded-кабель (обычный – solid). Это специальная витая пара, "мягкая», из которой и делаются патч-корды. Ведь обязательно рано или поздно понадобится патч-корд бо льшей длины, нежели есть из готовых под рукой (если вообще к тому времени останутся). Кроме того, можно (или нужно – как хотите) будет сделать короткие - 30-50 см, патч-корды для кроссировки линий СКС и активного оборудования в самом шкафу. Поэтому "берем на карандаш" еще пару-тройку упаковок коннекторов RJ45, в просторечьи – «фишки». И упаковку резиновых колпачков для них. Колпачки лучше брать мягкие и с прорезью под фиксатор «фишки», а не с «пупырышком"под фиксатор.
Мы уже добрались практически до сетевых интерфейсов на пользовательских компьютерах, но еще необходимы абонентские розетки. Кто-то против такой замечательной штуки, как Molex OFFICE BLOCK 2хRJ45? ;-)

Здесь надо определиться с количеством. Ведь есть и одинарные варианты. Снова берем план офиса... В определении мест установки розеток есть еще один важный момент –желательно на каждый кабинет добавить одну-две дополнительные линии СКС. Одну – просто «на всякий случай». А вдруг немного изменится планировка в кабинете или кому-то необходимо будет еще ноутбук подключить? Вторую – неплохо иметь в расчете на принт-сервер, для организации сетевой печати. Очень неплохо иметь на кабинет или офис один-два сетевых принтера, которые работают без проблем и капризов хозяина (или Windows).
Думаете – всё? Нет. Забыт еще один фактор, присутствующий любому офису – телефония. Очень неплохо подумать и об этом: если к некоторым рабочим местам должны быть проведены телефоны, то почему бы не сделать разводку в общей СКС? Ведь вопрос можно решить просто: кинуть линию-другую к необходимым местам, поставить рядом с RJ-45 еще и RJ-12 розетку, можно даже в одном корпусе (блоке). В розетку – DECT, к примеру, с несколькими трубками, а в шкаф проводим линию (линии) от АТС – их можно посадить на розетки, аккуратно приклеенные липучкой внутри и сбоку. Линии от рабочих мест – на них.
Вроде пора браться за кабель-канал и дюбель-гвозди? Да. Уже пора. Но это уже любому рукастому мужику понятно, не будем на этом долго останавливаться. Просто надо учесть количество укладываемых линий в кабель-канал. И, конечно же, необходим небольшой запас. Очень хорошо, если в офисе подвесной потолок, линии можно протягивать за ним прямо до рабочего места и спускать в кабель-канале по стене. При протяжке линий неплохо промаркировать их (как и в дальнейшем розетки). Самый простой метод – первая розетка слева от двери - №1, дальше по кругу.
Протянув линии, можно приступать к расколке патч-панели и розеток. Излишне говорить, что эта работа требует аккуратности и квалификации. Именно в этот момент нам пригодится маркировка линий – если все линии расколоть по порядку, то в дальнейшей эксплуатации СКС можно будет практически обойтись без карты (раскладки) монтажа, приблизительно такой:
Однако, эта карточка все-таки в будущем необходима. Пригодится обязательно.
При прокладке кабелей необходимо соблюдать несколько простых правил (именно простых, не будем сейчас углубляться в стандарты и прочие ISO):
Отдельно о последнем пункте. Помните анекдот про японскую поставку чего-то там? «Уважаемые заказчики! Мы не знаем зачем это вам, но мы все-таки решили положить в ящики по одному бракованному чипу на каждые десять тысяч, согласно вашим требованиям». Да, можно просто расколоть и забыть. Опытный монтажник не ошибается. Однако, действительно опытный монтажник обязательно проверит, и не только раскладку линии, но и качество.
Вот мы и дошли до самого интересного момента. Если простеньким и дешевым тестером мы проверим мелочь, то провести тесты и сертификацию линий – нет, никак не получится:
Molex SLT3 33.D0010
Какой выход? Очень не хочется оставлять вопрос качества линий нерешенным. Есть три варианта. Первый – купить хороший тестер, к примеру:
Но, увы, нам очень жалко $6000, пускай даже за такой прекрасный и необходимый прибор.

Второй вариант – пригласить знакомого админа или монтажника, у которого есть такой или аналогичный прибор. Конечно же, предварительно купив ящик хорошего пива. Полчаса работы, плюс пивной вечер в приятной компании знакомого.
Третий вариант – официально пригласить специалистов из какой-либо фирмы, которая оказывает такие услуги. И оплатить эти услуги. Это не так уж и много, особенно, если не требовать сертификата на бумаге.
Удаленные рабочие станции
"Закончив" (кавычки потому что надо сначала все-таки спланировать все и произвести необходимые закупки и переговоры) с работами на основном офисе, мы вспоминаем о складе и магазине.
Сейчас (в этих записках) рассмотрим не "мудреное"решение вроде VPN, а самое простое - организация связи компьютерных сетей с подсетями (рабочих станций с сетью) по выделенной линии. Эффективно, дешево и сердито. Кстати, выделёнки, конечно, следует завести в шкаф и подключить на розетки, как и телефоны.

В зависимости от вида и состояния кабеля, а также от расстояния Prestige 841 в паре с Prestige 841C обеспечивает следующую скорость обмена данными:
По направлению к абоненту – в пределах от 4.17 до 18.75 Мбит/с
по направлению от абонента – от 1,56 до 16,67 Мбит/с
суммарная пропускная способность линии может достигать 35 Мбит/с
Технические характеристики:
VDSL-мост Ethernet
Соединение локальных сетей на скорости 15 Мбит/с до 1.5 км
Plug&Play, прозрачен для всех протоколов
Работают в паре
Исполнение настольное
Энергонезависимая память (Flash ROM)
Размер: 181 x 128 x 30 мм
Этот вариант обойдется кошельку фирмы примерно в 300 долларов. И даст 18 Mb в каждую сторону, в идеале, конечно. Это VDSL.
При использовании Prestige 841 есть еще один плюс. Эти устройства имеют встроенный сплиттер, и мы можем получить "халявную"телефонию с удаленным местом. Достаточно включить в разъем “phone”с одной стороны телефон удаленного рабочего места, а с другой стороны – подключить офисную мини-АТС.
Если бриджи VDSL не "вытянут"линию, надо взглянуть на другие устройства, xDSL. Например – что-то из 79х серии ZyXEL, SHDSL.

Оптимизация аппаратной части и применение передовых технологий позволили не только уменьшить габариты устройства, но и снизить стоимость и улучшить функциональные характеристики. Prestige 791R обеспечивают симметричное соединение на скоростях до 2.3 МБит/с и могут работать на выделенной 2-проводной линии как в режиме "точка-точка", так и в качестве клиента концентратора провайдера Интернет.
Технические характеристики:
SHDSL-маршрутизатор
Поддержка G.991.2 на скорости до 2.3 Мбит/с симметрично
Соединение сетей или доступ в Интернет на больших расстояниях
Инкапсуляция PPPoA, PPPoE, RFC-1483
Маршрутизация TCP/IP, Full NAT, фильтрация пакетов
Поддержка IP Policy Routing , UPnP, резервирование соединения
Управление через консоль, Telnet, Web, SNMP
Идеальная скорость - 2,3Mb по двум проводам. Если "зарядить" 4 провода, скорость будет, соответственно, больше. Однако эти устройства обойдутся в большую сумму - 400-500 долларов за пару. В любом случае, грубо говоря, чем хуже качество линии, тем ниже скорость и больше затраты. Однако настройку (тюнинг) устройств отложим на будущее, это отдельный разговор, тем более что в случае с VDSL 841 это вообще не имеет слишком большого смыла. xDSL-устройства стоит поставить на полку в шкафу. Я ведь говорил, что она не будет пустовать.
Современный офис немыслим без интернета. Для подключения можем использовать ADSL-технологию, к примеру - ZyXEL Prestige 660.
Как описывает это устройство ZyXEL:
Модем P-660 R принадлежит к четвертому поколению ADSL-модемов и объединяет в одном устройстве функциональность, необходимую для подключения уже имеющейся офисной или домашней сети к Интернету: модем ADSL2+, маршрутизатор и межсетевой экран. Модем обеспечит ваш офис постоянным подключением в Интернет, работающим быстро и безопасно. Установка и обслуживание модема P-660 R проста и не доставит никаких проблем даже неподготовленным пользователям.
Основные преимущества ZyXEL Prestige 660:
Производитель также даёт следующие рекомендации по подключению: Домашним пользователям для подключения к услуге ADSL-доступа в интернет одного или нескольких компьютеров, если последние уже объединены в сеть, и скрытия внутренней структуры сети от атак из интернета. Бизнес-пользователям для подключения по ADSL небольших офисов, в которых уже есть локальная сеть, и остается только подключить ее к интернету или корпоративной сети.
Нас интересует последнее. Можно выбрать другую модель, но этой, в принципе, достаточно. О тонкостях настройки устройства и использовании канала подключения к интернет – позже.
Всё, теперь администратор может вздохнуть с облегчением, первый этап построения сети завершен. Если вам кажется, что даже это почти ерунда, словоблудие, продолжайте мучиться со старыми и новыми глюками, с линиями и коннекторами из некачественного кабеля и дешевок-розеток, с горящими портами и от этого "гадящими" в сети "коммутаторами" и т.п. Поверьте, очень многие этого уже "накушались" и готовы отдать денег (e.g. – сделать капиталовложения) подрядчикам, которые сделают всё, о чем говорилось, но за бо льшие деньги. А ведь "не так страшен черт, как его малюют".
Но окончательно расслабляться ещё рано, впереди - софтверное развитие сети, настройка (если хотите, «тюнинг») сетевых сервисов. Но это уже "совсем другая история"...
Автор выражает признательность и благодарность компании "ДатаСтрим"(www.datastream.by) за оборудование, консультации и реальную помощь - как в подготовке этих заметок, так и в работе.
Данный проект не претендует на звание первого места в мире и не рассматривается как конкурент FineReader , но надеюсь, что идея распознавания образов символов используя эйлеровую характеристику будет новой.
Основная идея состоит в том, что берется черно белое изображение, и считая, что 0 это белый пиксель, а 1 это черный пиксель, тогда все изображение будет представлять из себя матрицу из нулей и единиц. В таком случае, черно-белое изображение можно представить как набор фрагментов размером 2 на 2 пикселя, все возможные комбинации представлены на рисунке:

На каждом изображение pic1, pic2, ... изображен красный квадрат шага подсчёта в алгоритме, внутри которого один из фрагментов F с рисунка выше. На каждом шаге происходит суммирование каждого фрагмента, в результате для изображения Original получим набор: , далее он будет называть эйлеровой характеристикой изображения или характеристическим набором.
ЗАМЕЧАНИЕ: на практике значение F0 (для изображения Original это значение 8) не используется, поскольку является фоном изображения. Поэтому будут использоваться 15 значений, начиная с F1 до F15.
Идея распознания букв заключается в том, что мы заранее вычисляем эйлеровую характеристику для всех символов алфавита языка и сохраняем это в базу знаний. Затем для частей распозноваемого изображения будем вычислять эйлеровую характеристику и искать её в базе знаний.
Этапы распознавания:
Состав системы:
Итак, на вход мы имеем распозноваемое изображение, и цель из него сделать черно-белое, подходящее для начала процесса распознавания. Казалось бы, чего может быть проще, все белые пиксели считаем за 0, а все остальные остальные 1, но не все так просто. Текст на изображении может быть сглаженным и не сглаженным. Сглаженные символы смотрятся плавными и без углов, а не сглаженные будут выглядеть на современным мониторах с заметными глазу пикселями по контуру. С появлением LCD (жидкокристаллических) экранов были созданы ClearType (для Windows) и другие виды сглаживания, которые пользуясь особенностями матрицы монитора. Меняют цвета пиксели изображения текста, после чего он выглядит намного "мягче". Что бы увидеть результат сглаживания, можно напечатать какую то букву (или текст) к примеру в mspaint , увеличить масштаб, и ваш текст превратилась в какую то разноцветную мозаику.
![]()
В чем же дело? Почему на маленьком масштабе мы видим обычный символ? Неужели глаза нас обманываю? Дело в том, что пиксель LCD монитора состоит не из единого пикселя, который может принимать нужный цвет, а из 3 субпикселей 3 цветов, которых хватает для получения нужного цвета. Поэтому цель работы ClearType получить наиболее приятный глазу текст используя особенность матрицы LCD монитора, а это достигается с помощью субпиксельного рендеринга. У кого есть "Лупа" можете, с целью эксперимента, увеличить любое место включенного экрана и увидеть матрицу как на картинке ниже.
На рисунке показан квадрат из 3х3 пикселей LCD матрицы.
Внимание! Данная особенность усложняет получение черно белого изображения и очень сильно влияет на результат, поскольку не всегда даёт возможность получить такое же изображение, эйлеровая характеристика которого сохранена в базу знаний. Тем самым различие изображений заставляет выполнять эвристический анализ, которые не всегда может быть удачным.
Найденные в интернете алгоритмы преобразования цветного в черно-белое меня не устроили качеством. После их применения, образы символов подвергнутых сублепиксельному рендеренгу, становились разными по ширине, появлялись разрывы линий букв и непонятный мусор. В итоге решил получать черно-белого изображения путем анализа яркости пикселя. Черным считал все пиксели ярче (больше величины) 130 единиц, остальные белые. Данный способ не идеален, и все равно приводит к получению неудовлетворительного результата если меняется яркость текста, но он хотя бы получал схожие со значениями в базе знаний изображения. Реализацию можно посмотреть в классе LuminosityApproximator.
Изначальная задумка наполнения базы знаний была такая, что я для каждой буквы языка подсчитаю эйлеровую характеристику получаемого изображения символа для 140 шрифтов, которые установлены у меня на компьтере (C:\Windows\Fonts), добавлю ещё все варианты типы шрифтов (Обычный, Жирный , Курсив ) и размеры с 8 до 32, тем самым покрою все, или почти все, вариации букв и база станет универсальной, но к сожалению это оказалось не так хорошо как кажется. С такими условиями у меня получилось вот что:
Поэтому пришлось создать небольшую базу знаний, которая идет внутри Core модуля, и даёт возможность проверить функционал. Есть очень серьезная проблема при наполнении базы. Не все шрифты отображают символы небольшого размера корректно. Допустим символ "e" при отрисовке 8 размером шрифта по имени "Franklin Gothic Medium" получается как:
И мало чем похож на оригинал. При этом если добавить его в базу знаний, то это очень ухудшит результаты эвристики, так как вводит в заблуждение анализ символов похожих на этот. Д анный символ получался у разных шрифтов для разных букв. Сам процесс наполнения базы знания нужно контролировать, что бы каждое изображение символа, перед сохранением в базу знаний, проверялось человеком на соответствие букве. Но у меня, к сожалению, столько сил и времени нет.
Скажу сразу, что изначально я недооценил эту проблему с поиском и забыл о том, что символы могу состоять из нескольких частей. Мне казалось, что в ходе попиксельного прохождения я буду встречать символ, находить его части, если таковые имеются, объдинять их и анализировать. Обычный проход выглядил бы так, что я нахожу букву "H" (В базе знаний) и считаю, что все симолы нижие верхней точки и выше нижней точки относятся к текущей строке и должны ализировать в связке:

Но это идеальная ситуация, мне же в ходе распознования приходилось иметь дело с разобрванными изображениями, которые помимо всего могли иметь и огромное количество мусора, располагаемого рядом с текстом:

Что же такое эвристика при распозновании изображений?
Это процесс, в результате которого характеристический набор, не присутсвующий в базе знаний, получается распознать как правильную букву алфавита. Я долго думал, как можно производить анализ, и в итоге наболее удачным алгоритмом получился такой:
Пример начала распознования изображения image. В переменной result будет текст:
var recognizer = new TextRecognizer (container); var report = recognizer.Recognize(image); // Raw text. var result = report.RawText(); // List of all fragments and recognition state for each ones. var fragments = report.Symbols;Для наглядной демонстарции работы я написал WPF приложение. Запускается оно из проекта с именем "Qocr.Application.Wpf ". Пример окна с результатом распознования ниже:

Что бы распознать изображение потребуется:

При помощи множества анимаций на примере задачи распознавания цифр и модели перцептрона дано наглядное введение в процесс обучения нейросети.
Первое видео посвящено структуре компонентов нейронной сети, второе – ее обучению, третье – алгоритму этого процесса. В качестве задания для обучения взята классическая задача распознавания цифр, написанных от руки.
Детально рассматривается многослойный перцептрон – базисная (но уже достаточно сложная) модель для понимания любых более современных вариантов нейронных сетей.
Цель первого видео состоит в том, чтобы показать, что собой представляет нейронная сеть. На примере задачи распознавания цифр визуализируется структура компонентов нейросети. Видео имеет русские субтитры.
Представим, у вас есть число 3, изображенное в чрезвычайно низком разрешении 28х28 пикселей. Ваш мозг без труда узнает это число.

С позиций вычислительной техники удивительно, насколько легко мозг осуществляет эту операцию, при том что конкретное расположение пикселей сильно разнится от одного изображения к другому. Что-то в нашей зрительной коре решает, что все тройки, как бы они ни были изображены, представляют одну сущность. Поэтому задача распознавания цифр в таком контексте воспринимается как простая.
Но если бы вам предложили написать программу, которая принимает на вход изображение любой цифры в виде массива 28х28 пикселей и выдает на выходе саму «сущность» – цифру от 0 до 9, то эта задача перестала бы казаться простой.

Как можно предположить из названия, устройство нейросети в чем-то близко устройству нейронной сети головного мозга. Пока для простоты будем представлять, что в математическом смысле в нейросетях под нейронами понимается некий контейнер, содержащий число от нуля до единицы.
Так как наша сетка состоит из 28х28=784 пикселей, пусть есть 784 нейрона, содержащие различные числа от 0 до 1: чем ближе пиксель к белому цвету, тем ближе соответствующее число к единице. Эти заполняющие сетку числа назовем активациями нейронов. Вы можете себе представлять это, как если бы нейрон зажигался, как лампочка, когда содержит число вблизи 1 и гас при числе, близком к 0.

Описанные 784 нейрона образуют первый слой нейросети. Последний слой содержит 10 нейронов, каждый из которых соответствует одной из десяти цифр. В этих числах активация это также число от нуля до единицы, отражающее насколько система уверена, что входное изображение содержит соответствующую цифру.

Также есть пара средних слоев, называемых скрытыми, к рассмотрению которых мы вскоре перейдем. Выбор количества скрытых слоев и содержащихся в них нейронов произволен (мы выбрали 2 слоя по 16 нейронов), однако обычно они выбираются из определенных представлений о задаче, решаемой нейронной сетью.
Принцип работы нейросети состоит в том, что активация в одном слое определяет активацию в следующем. Возбуждаясь, некоторая группа нейронов вызывает возбуждение другой группы. Если передать обученной нейронной сети на первый слой значения активации согласно яркости каждого пикселя картинки, цепочка активаций от одного слоя нейросети к следующему приведет к преимущественной активации одного из нейронов последнего слоя, соответствующего распознанной цифре – выбору нейронной сети.
Прежде чем углубляться в математику того, как один слой влияет на следующий, как происходит обучение и как нейросетью решается задача распознавания цифр, обсудим почему вообще такая слоистая структура может действовать разумно. Что делают промежуточные слои между входным и выходным слоями?

В процессе распознавания цифр мы сводим воедино различные компоненты. Например, девятка состоит из кружка сверху и линии справа. Восьмерка также имеет кружок вверху, но вместо линии справа, у нее есть парный кружок снизу. Четверку можно представить как три определенным образом соединенные линии. И так далее.

В идеализированном случае можно ожидать, что каждый нейрон из второго слоя соотносится с одним из этих компонентов. И, когда вы, например, передаете нейросети изображение с кружком в верхней части, существует определенный нейрон, чья активация станет ближе к единице. Таким образом, переход от второго скрытого слоя к выходному соответствует знаниям о том, какой набор компонентов какой цифре соответствует.

Задачу распознавания кружка так же можно разбить на подзадачи. Например, распознавать различные маленькие грани, из которых он образован. Аналогично длинную вертикальную линию можно представить как шаблон соединения нескольких меньших кусочков. Таким образом, можно надеяться, что каждый нейрон из первого скрытого слоя нейросети осуществляет операцию распознавания этих малых граней.

Таким образом введенное изображение приводит к активации определенных нейронов первого скрытого слоя, определяющих характерные малые кусочки, эти нейроны в свою очередь активируют более крупные формы, в результате активируя нейрон выходного слоя, ассоциированной определенной цифре.

Будет ли так действовать нейросеть или нет, это другой вопрос, к которому вы вернемся при обсуждении процесса обучения сети. Однако это может служить нам ориентиром, своего рода целью такой слоистой структуры.
С другой стороны, такое определение граней и шаблонов полезно не только в задаче распознавания цифр, но и вообще задаче определения образов.

И не только для распознавания цифр и образов, но и других интеллектуальных задач, которые можно разбить на слои абстракции. Например, для распознавания речи из сырого аудио выделяются отдельные звуки, слоги, слова, затем фразы, более абстрактные мысли и т. д.
Для конкретики представим теперь, что цель отдельного нейрона в первом скрытом слое это определить, содержит ли картинка грань в отмеченной на рисунке области.

Первый вопрос: какие параметры настройки должны быть у нейросети, чтобы иметь возможность обнаружить этот шаблон или любой другой шаблон из пикселей.
Назначим числовой вес w i каждому соединению между нашим нейроном и нейроном из входного слоя. Затем возьмем все активации из первого слоя и посчитаем их взвешенную сумму согласно этим весам.

Так как количество весов такое же, как и число активаций, им также можно сопоставить аналогичную сетку. Будем обозначать зелеными пикселями положительные веса, а красными – отрицательные. Яркость пикселя будет соответствовать абсолютному значению веса.

Теперь, если мы установим все веса равными нулю, кроме пикселей, соответствующих нашему шаблону, то взвешенная сумма сведется к суммированию значений активаций пикселей в интересующей нас области.
Если же вы хотите, определить есть ли там именно ребро, вы можете добавить вокруг зеленого прямоугольника весов красные весовые грани, соответствующие отрицательным весам. Тогда взвешенная сумма для этого участка будет максимальной, когда средние пиксели изображения в этой части ярче, а окружающих их пиксели темнее.

Вычислив такую взвешенную сумму, вы можете получить любое число в широком диапазоне значений. Для того, чтобы оно попадало в необходимый диапазон активаций от 0 до 1, разумно использовать функцию, которая бы «сжимала» весь диапазон до интервала .

Часто для такого масштабирования используется логистическая функция сигмоиды . Чем больше абсолютное значение отрицательного входного числа, тем ближе выходное значение сигмоиды к нулю. Чем больше значение положительного входного числа, тем ближе значение функции к единице.

Таким образом, активация нейрона это по сути мера того, насколько положительна соответствующая взвешенная сумма. Чтобы нейрон не активировался при малых положительных числах, можно добавить к взвешенной сумме некоторое отрицательное число – сдвиг (англ. bias), определяющий насколько большой должна быть взвешенная сумма, чтобы активировать нейрон.

Разговор пока шел только об одном нейроне. Каждый нейрон из первого скрытого слоя соединен со всеми 784 пиксельными нейронами первого слоя. И каждое из этих 784 соединений будет иметь свой ассоциированный с ним вес. Также у каждого из нейронов первого скрытого слоя есть ассоциированный с ним сдвиг, добавляемый к взвешенной сумме перед «сжатием» этого значения сигмоидой. Таким образом, для первого скрытого слоя имеется 784х16 весов и 16 сдвигов.

Соединение между другими слоями также содержат веса и сдвиги, связанные с ними. Таким образом, для приведенного примера в качестве настраиваемых параметров выступают около 13 тыс. весов и сдвигов, определяющих поведение нейронной сети.
Обучить нейросеть задаче распознавания цифр значит заставить компьютер найти корректные значения для всех этих чисел так, чтобы это решило поставленную задачу. Представьте себе настройку всех этих весов и сдвигу вручную. Это один из действенных аргументов, чтобы трактовать нейросеть как черный ящик – мысленно отследить совместное поведение всех параметров практически невозможно.
Обсудим компактный способ математического представления соединений нейросети. Объединим все активации первого слоя в вектор-столбец. Все веса объединим в матрицу, каждая строка которой описывает соединения между нейронами одного слоя с конкретным нейроном следующего (в случае затруднений посмотрите описанный нами курс по ). В результате умножения матрицы на вектор получим вектор, соответствующий взвешенным суммам активаций первого слоя. Сложим матричное произведение с вектором сдвигов и обернем функцией сигмоиды для масштабирования интервалов значений. В результате получим столбец соответствующих активаций.

Очевидно, что вместо столбцов и матриц, как это принято в линейной алгебре, можно использовать их краткие обозначения. Это делает соответствующий программный код и проще, и быстрее, так как библиотеки машинного обучения оптимизированы под векторные вычисления.

Настало время уточнить то упрощение, с которого мы начали. Нейронам соответствуют не просто числа – активации, а функции активации, принимающие значения со всех нейронов предыдущего слоя и вычисляющие выходные значения в интервале от 0 до 1.

Фактически вся нейросеть это одна большая настраиваемая через обучения функция с 13 тысячами параметров, принимающая 784 входных значения и выдающая вероятность того, что изображение соответствует одной из десяти предназначенных для распознавания цифр. Тем не менее, не смотря на свою сложность, это просто функция, и в каком-то смысле логично, что она выглядит сложной, так как если бы она была проще, эта функция не была бы способна решить задачу распознавания цифр.
В качестве дополнения обсудим, какие функции активации используются для программирования нейронных сетей сейчас.
Затронем кратко тему функций, используемых для «сжатия» интервала значений активаций. Функция сигмоиды является примером, подражающим биологическим нейронам и она использовалась в ранних работах о нейронных сетях, однако сейчас чаще используется более простая ReLU функция, облегчающая обучение нейросети.

Функция ReLU соответствует биологической аналогии того, что нейроны могут находиться в активном состояни либо нет. Если пройден определенный порог, то срабатывает функция, а если не пройден, то нейрон просто остается неактивным, с активацией равной нулю.

Оказалось, что для глубоких многослойных сетей функция ReLU работает очень хорошо и часто нет смысла использовать более сложную для расчета функцию сигмоиды.
Возникает вопрос: как описанная в первом уроке сеть находит соответствующие веса и сдвиги только исходя из полученных данных? Об этом рассказывает второй урок.
В общем виде алгоритм состоит в том, чтобы показать нейросети множество тренировочных данных, представляющих пары изображений записанных от руки цифр и их абстрактных математических представлений.

В результате обучения нейросеть должна правильным образом различать числа из ранее не представленных, тестовых данных. Соответственно в качестве проверки обучения нейросети можно использовать отношение числа актов корректного распознавания цифр к количеству элементов тестовой выборки.

Откуда берутся данные для обучения? Рассматриваемая задача очень распространена, и для ее решения создана крупная база данных MNIST , состоящая из 60 тыс. размеченных данных и 10 тыс. тестовых изображений.

Концептуально задача обучения нейросети сводится к нахождению минимума определенной функции – функции стоимости. Опишем что она собой представляет.

Как вы помните, каждый нейрон следующего слоя соединен с нейроном предыдущего слоя, при этом веса этих связей и общий сдвиг определяют его функцию активации. Для того, чтобы с чего-то начать мы можем инициализировать все эти веса и сдвиги случайными числами.

Соответственно в начальный момент необученная нейросеть в ответ на изображение заданного числа, например, изображение тройки, выходной слой выдает совершенно случайный ответ.

Чтобы обучать нейросеть, введем функцию стоимости (англ. cost function), которая будет как бы говорить компьютеру в случае подобного результата: «Нет, плохой компьютер! Значение активации должно быть нулевым у всех нейронов кроме одного правильного».
Математически эта функция представляет сумму квадратов разностей между реальными значениями активации выходного слоя и их же идеальными значениями. Например, в случае тройки активация должна быть нулевой для всех нейронов, кроме соответствующего тройке, у которого она равна единице.

Получается, что для одного изображения мы можем определить одно текущее значение функции стоимости. Если нейросеть обучена, это значения будет небольшим, в идеале стремящимся к нулю, и наоборот: чем больше значение функции стоимости, тем хуже обучена нейросеть.
Таким образом, чтобы впоследствии определить, насколько хорошо произошло обучение нейросети, необходимо определить среднее значение функции стоимости для всех изображений обучающей выборки.
Это довольно трудная задача. Если наша нейросеть имеет на входе 784 пикселя, на выходе 10 значений и требует для их расчета 13 тыс. параметров, то функция стоимости является функцией от этих 13 тыс. параметров, выдает одно единственное значение стоимости, которое мы хотим минимизировать, и при этом в качестве параметров выступает вся обучающая выборка.


Как изменить все эти веса и сдвиги, чтобы нейросеть обучалась?
Для начала вместо того, чтобы представлять функцию с 13 тыс. входных значений, начнем с функции одной переменной С(w). Как вы, наверное, помните из курса математического анализа, для того, чтобы найти минимум функции, нужно взять производную.

Однако форма функции может быть очень сложной, и одна из гибких стратегий состоит в том, чтобы начать рассмотрение с какой-то произвольной точки и сделать шаг в направлении уменьшения значения функции. Повторяя эту процедуру в каждой следующей точке, можно постепенно прийти к локальному минимуму функции, как это делает скатывающийся с холма мяч.

Как на приведенном рисунке показано, что у функции может быть множество локальных минимумов, и то, в каком локальном минимуме окажется алгоритм зависит от выбора начальной точки, и нет никакой гарантии, что найденный минимум является минимальным возможным значением функции стоимости. Это нужно держать в уме. Кроме того, чтобы не «проскочить» значение локального минимума, нужно менять величину шага пропорционально наклону функции.
Чуть усложняя эту задачу, вместо функции одной переменной можно представить функцию двух переменных с одним выходным значением. Соответствующая функция для нахождения направления наиболее быстрого спуска представляет собой отрицательный градиент -∇С. Рассчитывается градиент, делается шаг в направлении -∇С, процедура повторяется до тех пор, пока мы не окажемся в минимуме.

Описанная идея носит название градиентного спуска и может быть применена для нахождения минимума не только функции двух переменных, но и 13 тыс., и любого другого количества переменных. Представьте, что все веса и сдвиги образуют один большой вектор-столбец w. Для этого вектора можно рассчитать такой же вектор градиента функции стоимости и сдвинуться в соответствующем направлении, сложив полученный вектор с вектором w. И так повторять эту процедуру до тех пор, пока функция С(w) не прийдет к минимуму.

Для нашей нейросети шаги в сторону меньшего значения функции стоимости будут означать все менее случайный характер поведения нейросети в ответ на обучающие данные. Алгоритм для эффективного расчета этого градиента называется метод обратного распространения ошибки и будет подробно рассмотрен в следующем разделе.
Для градиентного спуска важно, чтобы выходные значения функции стоимости изменялись плавным образом. Именно поэтому значения активации имеют не просто бинарные значения 0 и 1, а представляют действительные числа и находятся в интервале между этими значениями.
Каждый компонент градиента сообщает нам две вещи. Знак компонента указывает на направление изменения, а абсолютная величина – на влияние этого компонента на конечный результат: одни веса вносят больший вклад в функцию стоимости, чем другие.

Обсудим вопрос того, насколько соответствуют слои нейросети нашим ожиданиям из первого урока. Если визуализировать веса нейронов первого скрытого слоя обученной нейросети, мы не увидим ожидавшихся фигур, которые бы соответствовали малым составляющим элементам цифр. Мы увидим гораздо менее ясные паттерны, соответствующие тому как нейронная сеть минимизировала функцию стоимости.

С другой стороны возникает вопрос, что ожидать, если передать нейронной сети изображение белого шума? Можно было бы предположить, что нейронная сеть не должна выдать никакого определенного числа и нейроны выходного слоя не должны активироваться или, если и активироваться, то равномерным образом. Вместо этого нейронная сеть в ответ на случайное изображение выдаст вполне определенное число.

Хотя нейросеть выполняет операции распознавания цифр, она не имеет никаких представлений о том, как они пишутся. На самом деле такие нейросети это довольно старая технология, разработанная в 80-е-90-е годы. Однако понять работу такого типа нейросети очень полезно, прежде чем разбираться в современных вариантах, способных решать различные интересные проблемы. Но, чем больше вы копаетесь в том, что делают скрытые слои нейросети, тем менее интеллектуальной кажется нейросеть.
Рассмотрим пример современной нейросети для распознавания различных объектов реального мира.

Что произойдет, если перемешать базу данных таким образом, чтобы имена объектов и изображения перестали соответствовать друг другу? Очевидно, что так как данные размечены случайным образом, точность распознавания на тестовой выборке будет никудышной. Однако при этом на обучающей выборке вы будете получать точность распознавания на том же уровне, как если бы данные были размечены верным образом.
Миллионы весов этой конкретной современной нейросети будут настроены таким образом, чтобы в точности определять соответствие данных и их маркеров. Соответствует ли при этом минимизация функции стоимости каким-то паттернам изображений и отличается ли обучение на случайно размеченных данных от обучения на неверно размеченных данных?
Если вы обучаете нейросеть процессу распознавания на случайным образом размеченных данных, то обучение происходит очень медленно, кривая стоимости от количества проделанных шагов ведет себя практически линейно. Если же обучение происходит на структурированных данных, значение функции стоимости снижается за гораздо меньшее количество итераций.

Обратное распространение это ключевой алгоритм обучения нейронной сети. Обсудим вначале в общих чертах, в чем заключается метод.
Каждый шаг алгоритма использует в теории все примеры обучающей выборки. Пусть у нас есть изображение двойки и мы в самом начале обучения: веса и сдвиги настроены случайно, и изображению соответствует некоторая случайная картина активаций выходного слоя.
Мы не можем напрямую изменить активации конечного слоя, но мы можем повлиять на веса и сдвиги, чтобы изменить картину активаций выходного слоя: уменьшить значения активаций всех нейронов, кроме соответствующего 2, и увеличить значение активации необходимого нейрона. При этом увеличение и уменьшение требуется тем сильнее, чем дальше текущее значение отстоит от желаемого.

Сфокусируемся на одном нейроне, соответствующем активации нейрона двойки на выходном слое. Как мы помним, его значение является взвешенной суммой активаций нейронов предыдущего слоя плюс сдвиг, обернутые в масштабирующую функцию (сигмоиду или ReLU).
Таким образом, чтобы повысить значение этой активации, мы можем:

Из формулы взвешенной суммы можно заметить, что наибольший вклад в активацию нейрона оказывают веса, соответствующие связям с наиболее активированными нейронами. Стратегия, близкая к биологическим нейросетям заключается в том, чтобы увеличивать веса w i пропорционально величине активаций a i соответствующих нейронов предыдущего слоя. Получается, что наиболее активированные нейроны соединяются с тем нейроном, который мы только хотим активировать наиболее «прочными» связями.
Другой близкий подход заключается в изменении активаций нейронов предыдущего слоя a i пропорционально весам w i . Мы не можем изменять активации нейронов, но можем менять соответствующие веса и сдвиги и таким образом влиять на активацию нейронов.
Предпоследний слой нейронов можно рассматривать аналогично выходному слою. Вы собираете информацию о том, как должны были бы измениться активации нейронов этого слоя, чтобы изменились активации выходного слоя.
Важно понимать, что все эти действия происходят не только с нейроном, соответствующим двойке, но и со всеми нейронами выходного слоя, так как каждый нейрон текущего слоя связан со всеми нейронами предыдущего.

Просуммировав все эти необходимые изменения для предпоследнего слоя, вы понимаете, как должен измениться второй с конца слой. Далее рекурсивно вы повторяете тот же процесс для определения свойств весов и сдвигов всех слоев.
В результате вся операция на одном изображении приводит к нахождению необходимых изменений 13 тыс. весов и сдвигов. Повторяя операцию на всех примерах обучающей выборки, вы получаете значения изменений для каждого примера, которые далее вы можете усреднить для каждого параметра в отдельности.

Результат этого усреднения представляет вектор столбец отрицательного градиента функции стоимости.

Рассмотрение всей совокупности обучающей выборки для расчета единичного шага замедляет процесс градиентного спуска. Поэтому обычно делается следующее.
Случайным образом данные обучающей выборки перемешиваются и разделяются на подгруппы, например, по 100 размеченных изображений. Далее алгоритм рассчитывает шаг градиентного спуска для одной подгруппы.

Это не в точности настоящий градиент для функции стоимости, который требует всех данных обучающей выборки, но, так как данные выбраны случайным образом, они дают хорошую аппроксимацию, и, что важно, позволяют существенно повысить скорость вычислений.
Если построить кривую обучения такого модернизированного градиентного спуска, она будет похожа не на равномерный целенаправленный спуск с холма, а на петляющую траекторию пьяного, но делающего более быстрые шаги и приходящего также к минимуму функции.

Такой подход называется стохастическим градиентным спуском.
Разберемся теперь немного более формально в математической подоплеке алгоритма обратного распространения.
Начнем рассмотрение с предельно простой нейросети, состоящей из четырех слоев, где в каждом слое всего по одному нейрону. Соответственно у сети есть три веса и три сдвига. Рассмотрим, насколько функция чувствительна к этим переменным.

Начнем со связи между двумя последними нейронами. Обозначим последний слой L, предпоследний L-1, а активации лежащих в них рассматриваемых нейронов a (L) , a (L-1) .
Представим, что желаемое значение активации последнего нейрона, данное обучающим примеров это y, равное, например, 0 или 1. Таким образом, функция стоимости определяется для этого примера как
C 0 = (a (L) — y) 2 .
Напомним, что активация этого последнего нейрона задается взвешенной суммой, а вернее масштабирующей функцией от взвешенной суммы:
a (L) = σ (w (L) a (L-1) + b (L)).
Для краткости взвешенную сумму можно обозначить буквой с соответствующим индексом, например z (L) :
a (L) = σ (z (L)).
Рассмотрим как в значении функции стоимости сказываются малые изменения веса w (L) . Или математическим языком, какова производная функции стоимости по весу ∂C 0 /∂w (L) ?
Можно видеть, что изменение C 0 зависит от изменения a (L) , что в свою очередь зависит от изменения z (L) , которое и зависит от w (L) . Соответственно правилу взятия подобных производных, искомое значение определяется произведением следующих частных производных:
∂C 0 /∂w (L) = ∂z (L) /∂w (L) ∂a (L) /∂z (L) ∂C 0 /∂a (L) .

Рассчитаем соответствующие производные:
∂C 0 /∂a (L) = 2(a (L) — y)
То есть производная пропорциональна разнице между текущим значением активации и желаемым.
Средняя производная в цепочке является просто производной от масштабирующей функции:
∂a (L) /∂z (L) = σ"(z (L))
И наконец, последний множитель это производная от взвешенной суммы:
∂z (L) /∂w (L) = a (L-1)
Таким образом, соответствующее изменение определяется тем, насколько активирован предыдущий нейрон. Это соотносится с упоминавшейся выше идеей, что между загорающимися вместе нейронами образуется более «прочная» связь.

Конечное выражение:
∂C 0 /∂w (L) = 2(a (L) — y) σ"(z (L)) a (L-1)
Напомним, что определенная производная лишь для стоимости отдельного примера обучающей выборки C 0 . Для функции стоимости С, как мы помним, нужно производить усреднение по всем примерам обучающей выборки:
∂C/∂w (L) = 1/n Σ ∂C k /∂w (L)
 Полученное усредненное значение для конкретного w (L) является одним из компонентов градиента функции стоимости. Рассмотрение для сдвигов идентично приведенному рассмотрению для весов.
Полученное усредненное значение для конкретного w (L) является одним из компонентов градиента функции стоимости. Рассмотрение для сдвигов идентично приведенному рассмотрению для весов.
Получив соответствующие производные, можно продолжить рассмотрение для предыдущих слоев.
Однако как осуществить переход от слоев, содержащих по одному нейрону к исходно рассматриваемой нейросети. Все будет выглядеть аналогично, просто добавится дополнительный нижней индекс, отражающий номер нейрона внутри слоя, а у весов появятся двойные нижние индексы, например, jk, отражающие связь нейрона j из одного слоя L с другим нейроном k в слое L-1.

Конечные производные дают необходимые компоненты для определения компонентов градиента ∇C.

Потренироваться в описанной задаче распознавания цифр можно при помощи учебного репозитория на GitHub и упомянутого датасета для распознавания цифр MNIST .
Вредоносное ПО (malware) - это назойливые или опасные программы,...

Лучшие программы для восстановления данных с любых носителей информации....

Здравствуйте.Одна из самых распространенных причин, по которым тормозит...