Вредоносное ПО (malware) - это назойливые или опасные программы,...


Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.
Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все владельцы сайтов ведут свои архивы. Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно.
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Для того, чтобы отправиться в прошлое, нужно перейти на сайт archive.org и воспользоваться поисковой строкой.
Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.

Из этого видно, что сайт сайт был создан в 2012 году (Кстати, важно отметить, с помощью практически идеального хостинга Спринтхост — рекомендую!). Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта. Например, в 2015 году, пока можно будет увидеть только одну копию от 7 февраля.
Конечно, это потрясающий ресурс! Ведь здесь индексируются и архивируются все сайты интернета! Это не только скриншоты… Имея в руках такой инструмент, можно восстановить массу потерянной со временем информации.
Надо заметить, что, безусловно все восстановить однозначно не получится, так как если на страницах сайта используются элементы Java Script, или скрипты или графика взяты со стороннего сервера, то на восстановление такой информации рассчитывать не придется. Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что.
Пользуясь случаем, я сделала скриншоты и восстановила в памяти, как выглядел мой сайт, начиная с 2012 года. Любопытно посмотреть))
Сайт буквально недавно «родился»)) Январь 2012.. .

Проходит время, и хочется что-то изменить… Конец 2012-го.

Наверное, пора уже что-то менять. 2013-й. Это тема, которая и сегодня установлена на моем сайте.

К смене темы отношусь с осторожностью, так как помню последний «переезд», после которого несколько месяцев восстанавливала посещаемость сайта. Как-то не очень удачно получилось.
Надеюсь, что и моим читателям эта замечательная интернет-библиотека — «машина времени» сможет помочь перемещаться во времени, когда они этого захотят. Посмотрите, как выглядели раньше некоторые сайты, еще во времена своего зарождения. Какими раньше были google или яндекс, можно увидеть только на archive.org, аналогов у этого ресурса нет. Приятного путешествия, друзья!
У самого значимого в мире поисковика «все ходы записаны» — информация, попавшая в поле зрения поисковых роботов Google, раз и навсегда сохраняется в виде сохранённой копии. Эта копия иногда очень нужна веб-журналистам — чтобы получить важные, но уже удалённые сведения. Но как получить к ним доступ? Как осуществлять поиск по кэшу Google?
Если вы ищете что-то через Google, то найти сохраненную копию можно и через обычный интерфейс поисковика. Нажмите на зелёный треугольничек справа от ссылки на сайт, затем — на надпись «Сохраненная копия». Нажмите на неё — и посмотрите резервную копию имеющейся информации, которая попала в цепкие лапы «гугла».

Есть два способа:
Введите в адресную строку своего веб-браузера (Ghrome, Safari, Mozilla, Internet Explorer, Opera и т.д.) следующую информацию:
http://webcache.googleusercontent.com/search?q=cache:http://сайт Вместо сайт подставьте нужный вам сайт.
При желании можно посмотреть версию страницы без графики (только текст, своего рода режим Readability). Для этого достаточно нажать на «Текстовая версия» в правом верхнем углу экрана.

В браузере перед адресом страницы допишите слово «cache: ». В результате вместо самой страницы откроется её копия в кэше Google. Например:

Важно: Google в вашем браузере должен быть поиском по умолчанию. Если у вас не так — вводите «cache: » и адрес страницы в поисковой строке на google.com.
Вот и всё! Теперь вы можете искать в веб-кэше Google всё, что захотите — и когда захотите.
P.S. Хотите, чтобы запрос на кэш Google всегда был под рукой? Добавьте эту страницу в закладки. Как это сделать быстро и эффективно? Для Мас работает сочетание клавиш Cmd + D, для Windows — Ctrl + D.
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Сохраненная копия в Яндексе - это версия страницы, которая занесена в поисковой системы Яндекс.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
При просмотре выдачи результатов поисковика на введенный пользователем запрос в сниппете каждого сайта можно увидеть блок с дополнительной информацией. Одним из разделов блока с дополнительной информацией является «Сохраненная копия».

Чтобы понять, что из себя представляет сохраненная копия Яндекса, разберем простую аналогию. Представьте, что вы написали доклад или сочинение. Вы сдали работу, отправили ее на конкурс, но перед этим успели скопировать. Затем вам нужно еще раз сделать эту работу уже для другого конкурса. Чтобы не писать все заново, не восстанавливать в памяти все детали, вы достаете сохраненный файл и по ней пишите новое сочинение. Сохраненная страница Яндекса выполняет функцию данной копии. С ее помощью можно просмотреть сайт, если по тем или иным причинам нет доступа к интернет-ресурсу.
Прежде всего, отметим, что сохраненная копия в поисковой системе Яндекс - это важный инструмент SEO оптимизатора. С ее помощью можно увидеть, какая версия документа уже проиндексирована роботами поисковой системы и участвует в ранжировании, а какие страницы еще не прошли данный процесс. Таким образом, наличие сохраненной страницы в Яндексе - индикатор успешно пройденной индексации.
Все современные поисковые системы, и Яндекс не исключение, позволяют пользователям открыть нужные веб-документы через их индекс. Это можно сделать быстро с помощью специальных сервисов или вручную. В первом случае на помощь придут сервисы: Page Promoter в Firefox, RDS bar для Хроме и другие. Однако плагины периодически могут некорректно работать и выходить из строя, поэтому владеть ручным методом тоже нужно.
Открываем поисковик Яндекс и в строке поиска прописываем сам адрес нужной страницы или интересующий запрос. В результатах поиска мы видим, что в сниппете каждого результата есть маленькая стрелочка. Нажимаем на стрелочку и выбираем «Сохраненная копия». После этого мы посетим сайт, его сохраненную страницу от какой-то прошедшей даты.

Способ заключается в применении специальных расширений браузера/плагинов/онлайн сервисов. Наиболее популярным сегодня является «RDS bar». Интерфейс плагина более чем простой, с его помощью можно просмотреть последние изменения страницы, когда страницу в последний раз посещал робот, следовательно и копия предоставляется за это число. Если нужная страница не прошла индексацию Яндекса, ее сохраненная копия не будет отображаться в результатах выдачи поисковика.

Иногда при поиске сохраненной копии страницы можно не увидеть нужного пункта при нажатии на стрелочку в сниппете. Причин тому может быть несколько:

2. Вторая ситуация - в коде документа находится метатег “robots” и он имеет значение «noarchive» - запрет кэширования. Чтобы избежать падения трафика, необходимо внимательно настраивать подобные вещи.
Само по себе отсутствие копии не будет влиять как-то негативно на продвижение. А вот причины, которые привели к отсутствию могут повредить, поэтому разберитесь с ними.
Чем действительно может обернуться проблема с копиями страниц, так это затруднениями при работе с биржами ссылок.
Например, в Сеопульте сегодня есть параметр, который осуществляет контроль над тем, есть ли сохраненная копия Яндексе. Данный параметр называется NIC - No Index Cache. Он свидетельствует о том, что страница не имеет сохраненной копии. С такого ресурса не будут покупать ссылки, никому не хочется рисковать и платить за то, что может не принести пользы.
Как вы видите, сохраненная копия в Яндексе позволяет решить ряд проблем и оптимизировать использование интернет-трафика. Данные рекомендации позволят оперативно открывать и просматривать их.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.сайт/
Где http://www.сайт/ надо заменить на адрес искомого сайта.


Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса..
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Ищем файлы в папке ~/Library/Caches/Safari .
В адресной строке набираем chrome://cache
В адресной строке набираем opera://cache
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
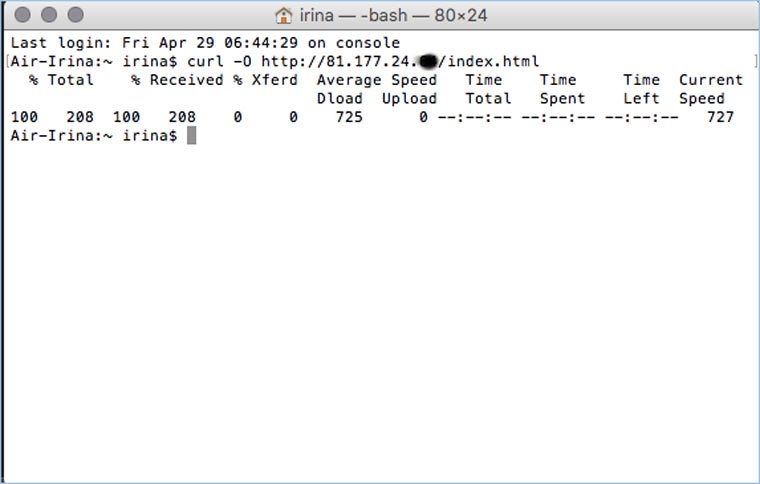
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:

После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com :
А о сборе информации про людей читайте в статьях и .
Иногда, зайдя на (ранее существовавшую) страницу, мы получаем 404 ошибку — страница не найдена. Эта страница удалена, сайт не доступен и т. д., но как просмотреть удалённую страницу ? Попробую дать ответ на этот вопрос и предложить четыре готовых варианта решения этой задачи.
Для экономии трафика и увеличения скорости загрузки страниц, браузеры используют кэш. Что такое кэш? Кэш (от англ. cache ) — дисковое пространство на компьютере, выделенное под временное хранение файлов, к которым относятся и веб-страницы.
Так что попробуйте просмотреть удаленную страницу из кэша браузера. Для этого — перейдите в автономный режим .
Примечание : просмотр страниц в автономном режиме возможен, только если пользователь посещал страницу ранее и она ещё не удалена из кэша.
Для Google Chrome , Яндекс.Браузер и др., автономный режим доступен только как эксперимент. Включите его на странице: chrome://flags/ — найдите там «Автономный режим кеша» и кликните ссылку «Включить ».
 Включение и выключение автономного режима в браузере Google Chrome
Включение и выключение автономного режима в браузере Google Chrome
В Firefox (29 и старше) откройте меню (кнопка с тремя полосками) и кликнуть пункт «Разработка » (гаечный ключ) , а потом пункт «Работать автономно ».
 Включение и выключение автономного режима в браузере Firefox
Включение и выключение автономного режима в браузере Firefox
В Opera кликните кнопку «Opera», найдите в меню пункт «Настройки », а потом кликните пункт «Работать автономно ».
 Как включить или отключить автономный режим в Opera?
Как включить или отключить автономный режим в Opera?
В Internet Explorer — нажмите кнопку Alt , (в появившемся меню) выберите пункт «Файл » и кликните пункт меню «Автономный режим ».

Уточню — в IE 11 разработчики удалили переключение автономного режима. Возникает вопрос — как отключить автономный режим в Internet Explorer 11? Выполнить обратные действия — не получится, сбросьте настройку браузера.
Для этого закройте запущенные приложения, в том числе и браузер. Нажмите комбинацию клавиш Win +R и (в открывшемся окне «Выполнить») введите: inetcpl.cpl , нажмите кнопку Enter . В открывшемся окне «Свойства: Интернет» перейдите на вкладку «Дополнительно ». На открывшейся вкладке найдите и кликните кнопку «Восстановить дополнительные параметры », а потом и появившуюся кнопку «Сброс… ». В окне подтверждения установите галочку «Удалить личные настройки » и нажмите кнопку «Сброс ».
Ранее я рассказывал , что пользователям поисковиков ненужно заходить на сайты — достаточно посмотреть копию страницы в поисковике, и это хороший способ решения нашей задачи.
В Google — используйте оператор info: , с указанием нужного URL-адреса. Пример:

В Яндекс — используйте оператор url: , с указанием нужного URL-адреса. Пример:

Наведите курсор мыши на (зелёный) URL-адрес в сниппете и кликните появившуюся ссылку «копия ».
Проблема в том, что поисковики хранят только последнюю проиндексированную копию страницы. Если страница удалена, со временем, она станет недоступна и в поисковиках.
Сервис WayBack Machine — Интернет архив, который содержит историю существования сайтов.
 Просмотр истории сайта на WayBack Machine
Просмотр истории сайта на WayBack Machine
Введите нужный URL-адрес, а сервис попытается найти копию указанной страницы в своей базе с привязкой к дате. Но сервис индексирует далеко не все страницы и сайты.
Простым и (к сожалению) пассивным сервис для создания копий веб-страниц является Archive.today . Получить доступ к удалённой странице можно, если она была скопирована другим пользователем в архив сервис. Для этого введите URL-адрес в первую (красную) форму и нажать кнопку «submit url ».

После этого, попробуйте найти страницу, используя вторую (синюю) форму.

Рекомендую! Подумал: А что делать, если страница не удалена? Бывает же так, что просто невозможно зайти на сайт. Нашел статью Виктора Томилина , которая так и называется «Не могу зайти на сайт » — где автор не просто описывает 4 способа решения проблемы, но и записал наглядное видео.
| в 22:40 | Изменить сообщение | 12 комментариев |
Вредоносное ПО (malware) - это назойливые или опасные программы,...

Лучшие программы для восстановления данных с любых носителей информации....

Здравствуйте.Одна из самых распространенных причин, по которым тормозит...