Вредоносное ПО (malware) - это назойливые или опасные программы,...


Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали первую часть , настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.


Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” - это вес H1, а “b” - это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения - это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
Input = H1*w1+H2*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.

Так что же такое, этот градиент? Градиент - это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка - это лыжник, а график функции - гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:


Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром - величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать - тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?


Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьи

H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат - 0.33, ошибка - 45%.
 Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (? output), следственно для скрытых нейронов мы уже будем брать вторую формулу (? hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (? output), следственно для скрытых нейронов мы уже будем брать вторую формулу (? hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Решение
O1output = 0.33
O1ideal = 1
Error = 0.45
O1 = (1 - 0.33) * ((1 - 0.33) * 0.33) = 0.148
Решение
H1output = 0.61
w5 = 1.5
?O1 = 0.148
H1 = ((1 - 0.61) * 0.61) * (1.5 * 0.148) = 0.053
Решение
H1output = 0.61
?O1 = 0.148
GRADw5 = 0.61 * 0.148 = 0.09
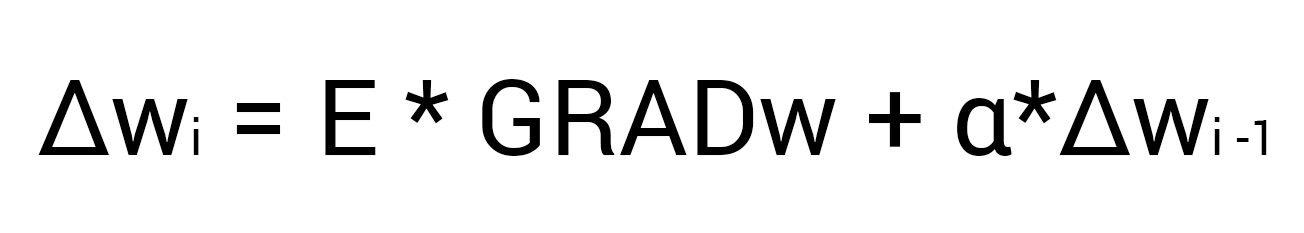
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) - скорость обучения, ? (альфа) - момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему?w5.
Решение
E = 0.7
? = 0.3
w5 = 1.5
GRADw5 = 0.09
?w5(i-1) = 0
W5 = 0.7 * 0.09 + 0 * 0.3 = 0.063
w5 = w5 + ?w5 = 1.563
Решение
H2output = 0.69
w6 = -2.3
?O1 = 0.148
E = 0.7
? = 0.3
?w6(i-1) = 0
H2 = ((1 - 0.69) * 0.69) * (-2.3 * 0.148) = -0.07
GRADw6 = 0.69 * 0.148 = 0.1
W6 = 0.7 * 0.1 + 0 * 0.3 = 0.07
W6 = w6 + ?w6 = -2.2
Решение
w1 = 0.45, ?w1(i-1) = 0
w2 = 0.78, ?w2(i-1) = 0
w3 = -0.12, ?w3(i-1) = 0
w4 = 0.13, ?w4(i-1) = 0
?H1 = 0.053
?H2 = -0.07
E = 0.7
? = 0.3
GRADw1 = 1 * 0.053 = 0.053
GRADw2 = 1 * -0.07 = -0.07
GRADw3 = 0 * 0.053 = 0
GRADw4 = 0 * -0.07 = 0
W1 = 0.7 * 0.053 + 0 * 0.3 = 0.04
?w2 = 0.7 * -0.07 + 0 * 0.3 = -0.05
?w3 = 0.7 * 0 + 0 * 0.3 = 0
?w4 = 0.7 * 0 + 0 * 0.3 = 0
W1 = w1 + ?w1 = 0.5
w2 = w2 + ?w2 = 0.73
w3 = w3 + ?w3 = -0.12
w4 = w4 + ?w4 = 0.13
Решение
I1 = 1
I2 = 0
w1 = 0.5
w2 = 0.73
w3 = -0.12
w4 = 0.13
w5 = 1.563
w6 = -2.2
H1input = 1 * 0.5 + 0 * -0.12 = 0.5
H1output = sigmoid(0.5) = 0.62
H2input = 1 * 0.73 + 0 * 0.124 = 0.73
H2output = sigmoid(0.73) = 0.675
O1input = 0.62* 1.563 + 0.675 * -2.2 = -0.51
O1output = sigmoid(-0.51) = 0.37
O1ideal = 1 (0xor1=1)
Error = ((1-0.37)^2)/1=0.39
Результат - 0.37, ошибка - 39%.
Обучение с учителем - это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя - этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу - нашел?w, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем?w всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода - это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму?w всех весов в той или иной группе.


Доступно показал насколько просто создать нейронную сеть для распознования картинок. Но есть одно но - то что он описал нейронной сетью не является. Перед его следующей статьей хочу рассказать вам как решить ту же задачу, но с использованием нейронной сети Кохонена.
Итак, распознавать мы будем цифры, написанные белым по черному, такие как эти:
Картинки 45 на 45 пикселей, а значит входов в нашу нейронную сеть будет 45 * 45.
Для простоты, распознаем только цифры от 0 до 5, поэтому нейронов у нас будет 6 - по одному на каждый ответ.
Cтруктура нашей нейросети:

Каждая связь входа сети с нейроном имеет свой вес. Импульс, проходя через связь, меняется: импульс = импульс * вес_связи.
Нейрон получает импульсы от всех входов и просто суммирует их. Нейрон набравший больший суммарный импульс побеждает. Все просто, реализуем!
Классы для представления элементов сети (C#):
// Вход
public class
Input
{
// Связи с нейронами
public
Link
OutgoingLinks;
}
// Связь входа с нейроном
public class
Link
{
// Нейрон
public
Neuron
Neuron;
// Вес связи
public double
Weight;
}
public class
Neuron
{
//Все входы нейрона
public
Link
IncomingLinks;
// Накопленный нейроном заряд
public double
Power { get; set; }
}
Создание и инициализация сети дело скучное, кому интересно - смотрите приложенный исходник. Остановлюсь лишь на том, что цвет пикселя это число от 0 до 255, причем 0 - это черный, 255 - белый, цвета между ними - градации серого.
Состояние класса KohonenNetwork это массив Input и массив Neuron:
public class
KohonenNetwork
{
private readonly
Input
_inputs;
private readonly
Neuron
_neurons;
...
}
Предположим, что наша сеть уже обучена. Тогда, чтобы узнать что изображено на картинке мы вызовем метод Handle, там все перемножится, сложится и найдется максимум:
// Пропустить вектор через нейронную сеть
public int
Handle(int
input)
{
for
(var
i = 0; i < _inputs.Length; i++)
{
var
inputNeuron = _inputs[i];
foreach
(var
outgoingLink in
inputNeuron.OutgoingLinks)
{
outgoingLink.Neuron.Power += outgoingLink.Weight * input[i];
}
}
var
maxIndex = 0;
for
(var
i = 1; i < _neurons.Length; i++)
{
if
(_neurons[i].Power > _neurons.Power)
maxIndex = i;
}
//снять импульс со всех нейронов:
foreach
(var
outputNeuron in
_neurons)
{
outputNeuron.Power = 0;
}
return
maxIndex;
}
Но перед тем как спрашивать у сети что-либо, её надо обучить. Для обучения предъявляем картинки и указываем что на них нарисовано:

Обучение - это изменение весов связей:
public void
Study(int
input, int
correctAnswer)
{
var
neuron = _neurons;
for
(var
i = 0; i < neuron.IncomingLinks.Length; i++)
{
var
incomingLink = neuron.IncomingLinks[i];
incomingLink.Weight = incomingLink.Weight + 0.5 * (input[i] - incomingLink.Weight);
}
}
После обучения на двух шрифтах, нейронная сеть различает цифры и из других шрифтов. В том числе будет пройден контрольный тест на таких вот цифрах:
Конечно, для расспознавания капчей такая поделка не годится - все перестает работать, стоит только сдвинуть, растянуть или повернуть изображение.
Однако всем становится понятно, что использовать нейронные сети не так уж и сложно, если начинать с простых примеров.
Сегодня на каждом углу то тут, то там кричат о пользе нейросетей. А вот что это такое, действительно понимают единицы. Если обратиться за объяснениями к Википедии, голова закружится от высоты понастроенных там цитаделей ученых терминов и определений. Если вы далеки от генной инженерии, а путанный сухой язык вузовских учебников вызывает только потерянность и никаких идей, то попробуем разобраться сообща в проблеме нейросетей.
Чтобы разобраться в проблеме, нужно узнать первопричину, которая кроется совсем на поверхности. Вспоминая Сару Коннор, с содроганием сердца понимаем, что некогда пионеры компьютерных разработок Уоррен Мак-Каллок и Уолтер Питтс преследовали корыстную цель создания первого Искусственного Интеллекта.
Нейронные сети – это электронный прототип самостоятельно обучаемой системы. Как и ребенок, нейросеть впитывает в себя информацию, пережевывает её, приобретает опыт и учится. В процессе обучения такая сеть развивается, растет и может делать собственные выводы и самостоятельно принимать решения.
Если мозг человека состоит из нейронов, то условно договоримся, что электронный нейрон – это некая воображаемая коробочка, у которой множество входных отверстий, а выходное – одно. Внутренний алгоритм нейрона определяется порядок обработки и анализа полученной информации и преобразования её в единый полезный ком знаний. В зависимости от того, насколько хорошо работают входы и выходы, вся система или соображает быстро, или, наоборот, может тормозить.
Важно : Как правило, в нейронных сетях используется аналоговая информация.
Повторимся, что входных потоков информации (по-научному эту связь первоначальной информации и наш “нейрон” называют синапсами) может быть множество, и все они носят разных характер и имеют неравную значимость. Например, человек воспринимает окружающий мир через органы зрения, осязания и обоняния. Логично, что зрение первостепеннее обоняния. Исходя из разных жизненных ситуаций мы используем определенные органы чувств: в полной темноте на первый план выходят осязание и слух. Синапсы у нейросетей по такой же аналогии в различных ситуациях будут иметь разную значимость, которую принято обозначать весом связи. При написании кода устанавливается минимальный порог прохождения информации. Если вес связи выше заданного значения, то результат проверки нейроном положительный (и равен единице в двоичной системе), если меньше – то отрицательный. Логично, что, чем выше задана планка, тем точнее будет работа нейросети, но тем дольше она будет проходить.
Чтобы нейронная сеть работала корректно, нужно потратить время на её обучение – это и есть главное отличие от простых программируемых алгоритмов. Как и маленькому ребенку, нейросети нужна начальная информационная база, но если написать первоначальный код корректно, то нейросеть уже сама сможет не просто делать верный выбор из имеющейся информации, но и строить самостоятельные предположения.
При написании первичного кода объяснять свои действия нужно буквально по пальцам. Если мы работаем, например, с изображениями, то на первом этапе значение для нас будет иметь её размер и класс. Если первая характеристика подскажет нам количество входов, то вторая поможет самой нейросети разобраться с информацией. В идеале, загрузив первичные данные и сопоставив топологию классов, нейросеть далее уже сама сможет классифицировать новую информацию. Допустим, мы решили загрузить изображение 3х5 пикселей. Простая арифметика нам подскажет, что входов будет: 3*5=15. А сама классификация определит общее количество выходов, т.е. нейронов. Другой пример: нейросети необходимо распознать букву “С”. Заданный порог – полное соответствие букве, для этого потребуется один нейрон с количеством входов, равных размеру изображения.
Допустим, что размер будет тот же 3х5 пикселей. Скармливая программе различные картинки букв или цифр, будем учить её определять изображение нужного нам символа.
Как и в любом обучении, ученика за неправильный ответ нужно наказывать, а за верный мы ничего давать не будем. Если верный ответ программа воспринимает как False, то увеличиваем вес входа на каждом синапсе. Если же, наоборот, при неверном результате программа считает результат положительным или True, то вычитаем вес из каждого входа в нейрон. Начать обучение логичнее со знакомства с нужным нам символом. Первый результат будет неверным, однако немного подкорректировав код, при дальнейшей работе программа будет работать корректно. Приведенный пример алгоритма построения кода для нейронной сети называется парцетроном.

Бывают и более сложные варианты работы нейросетей с возвратом неверных данных, их анализом и логическими выводами самой сети. Например, онлайн-предсказатель будущего вполне себе запрограммированная нейросеть. Такие проги способны обучаться как с учителем, так и без него, и носят название адаптивного резонанса. Их суть заключается в том, что у нейронов уже есть свои представления об ожидании о том, какую именно информацию они хотят получить и в каком виде. Между ожиданием и реальностью проходит тонкий порог так называемой бдительности нейронов, которая и помогает сети правильно классифицировать поступающую информацию и не упускать ни пикселя. Фишка АР нейросети в том, что учится она самостоятельно с самого начала, самостоятельно определяет порог бдительности нейронов. Что, в свою очередь, играет роль при классифицировании информации: чем бдительнее сеть, тем она дотошнее.
Самые азы знаний о том, что такое нейросети, мы получили. Теперь попробуем обобщить полученную информацию. Итак, нейросети – это электронный прототип мышлению человека. Они состоят из электронных нейронов и синапсов – потоков информации на входе и выходе из нейрона. Программируются нейросети по принципу обучения с учителем (программистом, который закачивает первичную информацию) или же самостоятельно (основываясь на предположения и ожидания от полученную информацию, которую определяет всё тот же программист). С помощью нейросети можно создать любую систему: от простого определения рисунка на пиксельных изображениях до психодиагностики и экономической аналитики.

Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число - ответ. Теперь о самих нейронных сетях.

Нейронная сеть - это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей - это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг . Самыми распространенными применениями нейронных сетей является:
Классификация - распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание - возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание - в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.

Нейрон - это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ - это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр - вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример - смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов - это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.

В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H - скрытый нейрон, а буквой w - веса. Из формулы видно, что входная информация - это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации - это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия - это диапазон значений.
Линейная функция

Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид

Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет - это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключительного или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.

Важно
не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка - это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.

Root MSE


Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE.
Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
В данной статье собраны материалы - в основном русскоязычные - для базового изучения искусственных нейронных сетей.
Искусственная нейронная сеть, или ИНС - математическая модель, а также ее программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей - сетей нервных клеток живого организма. Наука нейронных сетей существует достаточно давно, однако именно в связи с последними достижениями научно-технического прогресса данная область начинает обретать популярность.
Начнем подборку с классического способа изучения - с помощью книг. Мы подобрали русскоязычные книги с большим количеством примеров:
Д. Форсайт, Компьютерное зрение. Современный подход. 2004 г.
Компьютерное зрение – это одна из самых востребованных областей на данном этапе развития глобальных цифровых компьютерных технологий. Оно требуется на производстве, при управлении роботами, при автоматизации процессов, в медицинских и военных приложениях, при наблюдении со спутников и при работе с персональными компьютерами, в частности, поиске цифровых изображений.
Нет ничего доступнее и понятнее, чем визуальное обучение при помощи видео:
Ранее у нас публиковался уже курс #neuralnetwork@tproger по нейронным сетям. В этом списке публикации для вашего удобства расположены в порядке изучения.
Вредоносное ПО (malware) - это назойливые или опасные программы,...

Лучшие программы для восстановления данных с любых носителей информации....

Здравствуйте.Одна из самых распространенных причин, по которым тормозит...